Microsoft DP-203 Bundle
- Exam: DP-203 Data Engineering on Microsoft Azure
- Exam Provider: Microsoft

Latest Microsoft DP-203 Exam Dumps Questions
Microsoft DP-203 Exam Dumps, practice test questions, Verified Answers, Fast Updates!
-
-

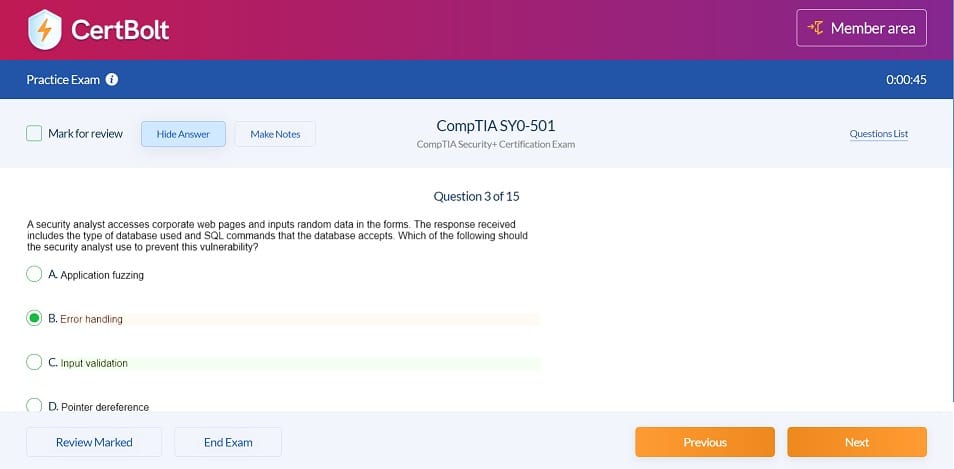
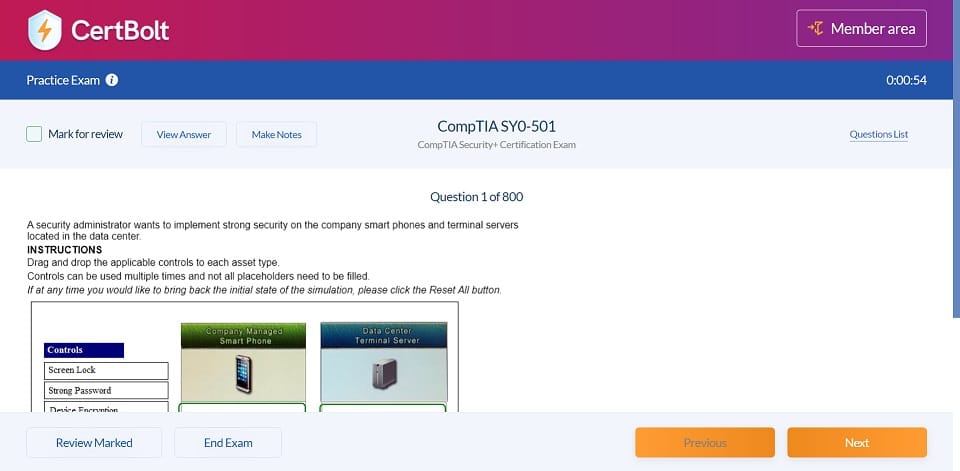
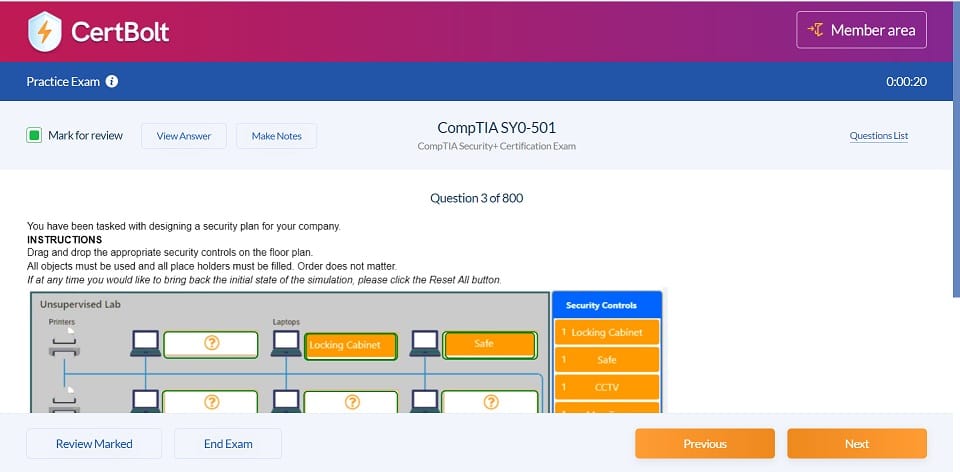
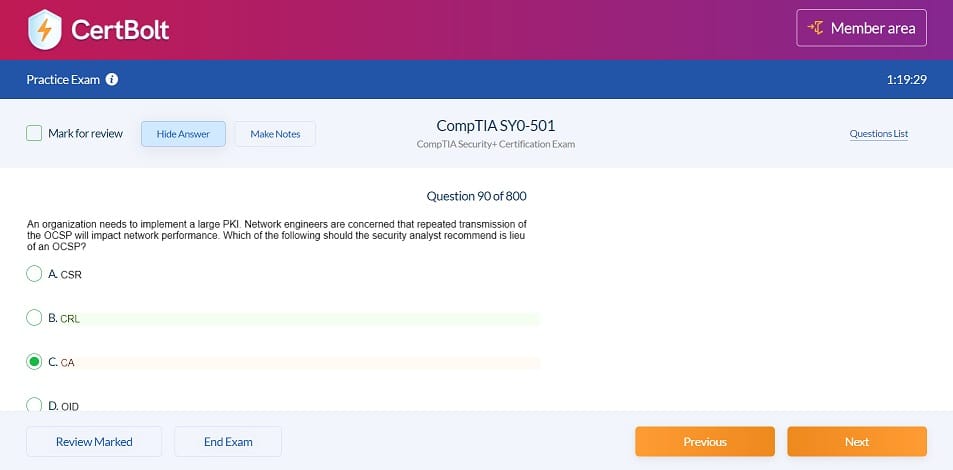
DP-203 Questions & Answers
397 Questions & Answers
Includes 100% Updated DP-203 exam questions types found on exam such as drag and drop, simulation, type in, and fill in the blank. Fast updates, accurate answers for Microsoft Azure DP-203 exam. Exam Simulator Included!
-

DP-203 Online Training Course
262 Video Lectures
Learn from Top Industry Professionals who provide detailed video lectures based on 100% Latest Scenarios which you will encounter in exam.
-

DP-203 Study Guide
1325 PDF Pages
Study Guide developed by industry experts who have written exams in the past. Covers in-depth knowledge which includes Entire Exam Blueprint.
-
-
Microsoft Azure DP-203 Exam Dumps, Microsoft Azure DP-203 practice test questions
100% accurate & updated Microsoft Azure certification DP-203 practice test questions & exam dumps for preparing. Study your way to pass with accurate Microsoft Azure DP-203 Exam Dumps questions & answers. Verified by Microsoft experts with 20+ years of experience to create these accurate Microsoft Azure DP-203 dumps & practice test exam questions. All the resources available for Certbolt DP-203 Microsoft Azure certification practice test questions and answers, exam dumps, study guide, video training course provides a complete package for your exam prep needs.
Core Skills and Responsibilities of an Azure Data Engineer (DP-203)
In the realm of modern data architecture, Azure Data Engineers serve as the bridge between massive volumes of raw information and the high-value insights organizations depend on. Far from being an entry-level role, this position demands a firm grasp of cloud-native data technologies, engineering principles, and architectural fluency in distributed systems. To succeed, a strong foundation in key technical skills is essential.
Understanding the Azure Data Engineering Role
Azure Data Engineers are responsible for designing, building, and maintaining the systems that ingest, process, and serve data for analytical and operational use. These professionals manage both structured and unstructured data and ensure that it flows seamlessly from its source to its destination—often across multiple regions, formats, and tools.
The core responsibility is not just to move data, but to make it usable. This includes building reliable ingestion pipelines, performing necessary transformations, applying governance standards, and ensuring scalability and security throughout the data lifecycle.
Data engineers must be proficient in creating data models, working with both batch and real-time processing frameworks, and securing the data at rest and in transit. These requirements call for knowledge beyond basic ETL tasks, stretching into data orchestration, lakehouse architecture, partitioning strategies, and storage optimization.
Foundational Skills Required
To begin the path toward this certification, a solid understanding of several technical areas is necessary. These include:
Data pipeline design and orchestration: Ability to build robust data flows across various environments using cloud-native tools.
Programming languages: Comfort with Python and Java is essential, especially for scripting, transformation logic, and working with APIs.
Data querying and modeling: A strong grip on SQL is critical for defining relationships, aggregations, and advanced filtering operations across large datasets.
Database and storage systems: Knowledge of partitioned tables, polybase integration, and various storage formats like Parquet, Delta, and Avro is valuable.
Security and compliance: Understanding role-based access controls, encryption mechanisms, and data classification policies.
Performance tuning: Skills to monitor and optimize data processes to improve query speeds, reduce costs, and ensure system efficiency.
Azure Data Engineers need not only to possess these skills but also to apply them creatively in solving problems for businesses, making data accessible for analysts and AI systems alike.
Real-World Responsibilities That Go Beyond the Exam
While preparing for the DP-203 certification can help formalize these skills, the actual responsibilities on the job often extend deeper into design thinking and strategic decision-making.
At a practical level, Azure Data Engineers are tasked with:
Architecting end-to-end data solutions, from ingestion to delivery
Designing fault-tolerant pipelines that adapt to schema changes
Ensuring data lineage is traceable for audit and compliance purposes
Managing access control and ensuring only authorized users can view or alter datasets
Integrating telemetry data to support operational monitoring
Working with cross-functional teams to meet evolving data needs
The certification validates that an individual can do all of the above within the Azure ecosystem, applying best practices for performance, reliability, and security.
A Deep Dive into the Role of Data Orchestration
One of the less-discussed but critically important elements of the Azure Data Engineer’s role is orchestration. This refers to the sequencing, scheduling, and coordination of different tasks in the data pipeline. It’s not enough to move data—it has to be moved reliably, on time, and with awareness of dependencies between sources.
Orchestration tools and techniques allow engineers to automate complex workflows. Whether transforming terabytes of log data overnight or streaming transactional data in real time, orchestration ensures that pipelines run predictably and respond gracefully to failures. Retries, notifications, and lineage tracking must all be built into the system to ensure operational resilience.
This orchestration knowledge is not simply a checkbox for the exam. In production environments, it's vital for maintaining data SLAs, ensuring accurate reporting, and minimizing downtime.
Engineering Secure and Compliant Data Systems
Security is no longer a concern delegated to another team—it is a responsibility deeply embedded within the data engineering workflow. Azure Data Engineers are expected to enforce security policies through technical controls such as:
Tokenized access credentials
Role-based authorization
Encryption of data in motion and at rest
Network isolation through private endpoints and service endpoints
They must also support regulatory compliance by ensuring personal or sensitive data is processed according to jurisdictional standards. Data retention policies, classification schemes, and masking strategies are commonly employed.
Failing to integrate security at every stage of a data pipeline doesn’t just lead to technical debt—it poses organizational risk. That’s why the DP-203 certification assesses not just engineering prowess, but also the ability to implement responsible, compliant data solutions.
The Complexity of Distributed Data Design
Azure environments are inherently distributed, and so is data within them. From data lakes to data warehouses and streaming platforms, Azure Data Engineers must be capable of designing distributed systems that are performant and cost-efficient.
Designing a partitioning strategy, for example, may seem minor but can impact query time, storage costs, and system scalability. Choosing between Delta Lake and traditional Parquet formats, or between different ingestion mechanisms like event streaming and batch import, can shape how quickly data becomes usable.
These decisions require an understanding of not just the tools, but of how data is going to be consumed—whether for business reporting, machine learning, or real-time dashboards.
Aligning Data Strategy with Business Outcomes
A vital and often underestimated responsibility of Azure Data Engineers is aligning their technical decisions with business outcomes. Engineers must ask questions like:
How quickly does this data need to be available for analysis?
What metrics does leadership care about?
What SLA must this data pipeline meet?
What is the cost profile of this design, and how can we optimize it?
Azure Data Engineers must often act as the translator between executive expectations and technical constraints. The ability to connect business needs with scalable architectures separates those who merely pass exams from those who drive real impact in organizations.
Bridging the Gap Between Development and Operations
As organizations move towards integrated DevOps and DataOps practices, Azure Data Engineers must understand how to blend software development principles with operational data engineering. This includes:
Version control for data pipelines
CI/CD for data workflows
Automated testing of data quality
Monitoring of pipeline health and failure alerts
Understanding how to implement pipelines that are both agile and reliable gives engineers the agility to respond to business changes and the confidence that systems won’t break silently in production.
Decoding the DP-203 Exam – Domains, Expectations, and Practical Preparation
The DP-203 exam measures a candidate’s ability to apply real-world Azure data engineering skills across a spectrum of scenarios. It validates technical knowledge in managing scalable data processing solutions, implementing secure data storage and transformation, and enabling analytics capabilities across platforms. But beyond the credential itself, preparing for this exam builds depth in key engineering practices.
Understanding the exam domains and the type of tasks candidates are expected to perform is essential to approach this certification not just as a test, but as a way to reinforce professional capability.
Understanding the DP-203 Certification Objective
The DP-203 certification aims to validate a data engineer's ability to design and implement data solutions that are efficient, secure, and scalable. It places strong emphasis on four key domains. Each domain tests skills aligned to specific responsibilities performed by Azure Data Engineers on a daily basis.
Candidates should prepare for real-world case scenarios, not isolated facts. That’s why deep comprehension of how Azure services interact with each other and integrate into data pipelines is critical.
Exam Structure and Format
The DP-203 exam typically lasts around 100–120 minutes. The number of questions may vary, but it's generally around 40–60. These questions cover a wide range of task types including multiple-choice, drag-and-drop, case studies, and scenario-based simulations.
Some questions will test theoretical understanding, while others will require practical application of knowledge in realistic cloud-based environments. Questions can appear deceptively simple but may contain traps for those unfamiliar with Azure service limitations or default behaviors.
There is no publicly fixed pass mark, as the scoring is weighted based on question complexity, but a score of 700 out of 1000 is typically required.
Domain 1: Design and Implement Data Storage (40–45%)
This is the largest and most weighted domain. It assesses a candidate's ability to implement solutions using relational and non-relational data stores.
Key skills measured include:
Designing partitioning and indexing strategies for data warehouses
Implementing Azure Synapse Analytics dedicated and serverless pools
Designing and optimizing storage solutions using Data Lake Storage Gen2
Managing hierarchical namespaces and access control lists
Using PolyBase for external table queries across heterogeneous data sources
Implementing Cosmos DB with appropriate consistency levels and partition keys
Selecting the right database technologies for transactional, analytical, and real-time workloads
This domain expects familiarity with various file formats such as Avro, JSON, Delta, and Parquet. Candidates must know how to design a schema for efficient storage and retrieval and apply cost-saving strategies like hot/cold tiering or lifecycle policies.
Mistakes often come from underestimating the nuances of partition elimination, schema drift, or consistency guarantees in NoSQL workloads.
Domain 2: Design and Develop Data Processing (25–30%)
This domain measures the ability to create and manage data pipelines using Azure-native tools. It focuses heavily on processing methods, pipeline orchestration, error handling, and real-time ingestion.
Candidates should be skilled in:
Building batch and stream data pipelines using Azure Data Factory and Azure Synapse Pipelines
Authoring pipelines using data flows, mapping transformations, and custom scripts
Handling schema drift, malformed records, and null values
Ingesting data from various sources including REST APIs, file shares, and event hubs
Implementing Azure Stream Analytics for real-time ingestion
Designing scalable solutions with Databricks or Spark for heavy transformation workloads
This area requires not just theoretical understanding but actual design skills. Candidates must understand how different activities in a pipeline interact, the costs associated with each, and how to implement data flows that are resilient to failure.
Knowing how to design pipelines that retry upon transient failure, validate file schema before loading, or dynamically branch based on metadata can be the difference between passing and failing.
Domain 3: Design and Implement Data Security (10–15%)
Although the smallest section, this domain often presents the most subtle challenges. It assesses a candidate’s ability to apply governance, access control, and secure data movement throughout the pipeline.
Skills measured here include:
Implementing data encryption at rest and in transit
Configuring private endpoints, service endpoints, and network rules
Enabling managed identity authentication for services
Implementing Azure role-based access control (RBAC) and access control lists (ACLs)
Applying column-level and row-level security in Synapse and dedicated SQL pools
Auditing access and setting data classification labels
Candidates should understand how security propagates between services and how misconfigurations in identity management can expose sensitive data. This section also tests knowledge of identity delegation, service principals, and shared access signatures.
Security best practices are often integrated into case-based questions where candidates must determine whether a data lake, database, or stream is properly protected based on shared context.
Domain 4: Monitor and Optimize Data Solutions (10–15%)
Monitoring and optimization go far beyond dashboards. This domain assesses the ability to observe system behavior and take action to ensure smooth operations.
Important skills in this section include:
Implementing logging and telemetry using Azure Monitor and Log Analytics
Creating alerts for failed pipelines or performance degradation
Identifying bottlenecks in data flows and applying optimization techniques
Optimizing distributed processing jobs using parallelism and caching
Managing cost by selecting appropriate resources and scheduling pipelines
Troubleshooting memory and I/O issues in Spark or Synapse
Success in this area depends on understanding telemetry at scale and implementing feedback loops. Candidates should be comfortable identifying long-running queries, tuning data skew, and eliminating unnecessary shuffles in Spark operations.
Often, exam questions present slow performance scenarios and ask for the best course of action. Being able to diagnose the root cause from symptoms is key.
Common Pitfalls in Exam Preparation
Many candidates preparing for DP-203 make a few avoidable errors:
Focusing too much on memorizing portal settings rather than understanding architectural principles
Underestimating the complexity of orchestration in multi-step pipelines
Ignoring real-time processing and treating everything as batch
Overlooking integration patterns between services (for example, how ADF triggers Spark jobs)
Skipping topics like versioning, cost estimation, and lifecycle policies
The exam is less about individual tools and more about stitching them together correctly under constraints. A question might describe a scenario where multiple services are involved, and understanding data flow dependencies becomes essential.
Suggested Preparation Approach (Without Resource Names)
While everyone learns differently, successful candidates often follow a practical, layered approach:
Start with broad architecture knowledge: Understand how the Azure data ecosystem is organized, what services exist, and how they interact in end-to-end pipelines.
Get hands-on with pipelines: Build a few working data solutions involving ingestion, transformation, storage, and delivery. Simulate edge cases like schema drift, malformed rows, or network issues.
Dive into service-specific behavior: Focus on configuration options, limits, and trade-offs within key services such as Synapse, Data Lake Storage, and Data Factory.
Understand common design patterns: Learn how to deal with large data volumes using partitioning and bucketing strategies, stream processing with windows and watermarking, and multi-layered data lake architecture.
Simulate failure scenarios: Build pipelines that are intentionally flawed and fix them. Add fault tolerance, retries, and error routing.
Write sample queries and test optimizations: Use serverless SQL pools or Spark to practice writing performance-tuned queries, including joins, aggregations, and filtering.
Map exam domains to your skills: Review your confidence level in each area and focus your study time accordingly. Pay extra attention to your weakest domain.
How the DP-203 Exam Aligns with On-the-Job Skills
The DP-203 exam reflects real data engineering tasks much more closely than many theoretical tests. Candidates are expected to architect solutions under constraints, adapt to dynamic data, and consider operational stability alongside scalability.
On the job, engineers are often given business requirements and expected to design pipelines that handle exceptions, scale automatically, and stay within budget. These same pressures are reflected in scenario-based questions.
For example, you may be asked to improve the reliability of a pipeline that intermittently fails due to timeouts. The correct solution might involve increasing timeouts, parallelizing steps, or restructuring the workflow. The correct choice depends on recognizing the architectural bottleneck, not memorizing default settings.
Understanding the DP-203 Exam's Core Domains
The DP-203 exam for Microsoft Azure Data Engineers centers around practical expertise in managing, designing, and implementing data solutions. This certification isn't about memorizing theory but rather applying real-world skills to complex data environments. It evaluates an individual's ability to work across large-scale data architectures, including batch and stream processing, secure storage, and performance optimization.
The exam is split into four major domains. The first and most heavily weighted domain focuses on data storage. Candidates must understand how to design optimal storage structures, partition strategies, and serving layers. The second domain, centered on data processing, demands fluency in building ingestion pipelines and supporting batch and stream-processing solutions. The remaining two domains cover data security and monitoring optimization—both of which are essential for a modern data platform to remain secure, cost-effective, and resilient.
Building Data Storage Solutions That Scale
A major component of the DP-203 certification is the ability to design scalable and performant storage structures. A successful Azure Data Engineer must go beyond knowing the types of storage accounts or blob tiers. They need to evaluate the business requirements to decide between using a lakehouse, traditional relational stores, or hybrid designs.
Designing the right structure involves balancing cost, accessibility, and data volume. It requires understanding how hot and cold data are treated differently within Azure storage accounts. Engineers must also define logical data structures that align with analytical and transactional needs. Partitioning strategies must consider access patterns and latency requirements to avoid bottlenecks in downstream data consumption.
The implementation stage demands precision. Whether using Data Lake Gen2, Synapse SQL Pools, or Cosmos DB, the physical configuration must meet the logical model without introducing operational risk. Furthermore, engineers must plan for future scalability, accommodating data growth without reengineering the storage solution.
Managing Data Ingestion and Processing Pipelines
The next priority is mastering the creation of data pipelines that ingest and transform data in real-time and batch modes. In the DP-203 context, candidates must understand ingestion tools such as Azure Data Factory and Azure Synapse Pipelines. They must also know when to use event-driven components like Event Hubs or IoT Hub for real-time workloads.
The ingestion phase involves not only pulling data from disparate sources but also enforcing schema consistency, metadata tagging, and data quality checks. Once data is ingested, transformation comes into play. Here, knowledge of mapping data flows, dynamic content, parameterization, and script activities becomes essential. These skills allow engineers to reshape data in a form suitable for analytics, machine learning, or business intelligence.
Batch processing workloads often involve transformation and movement of large data volumes during off-peak hours, minimizing cost and optimizing throughput. Stream processing workloads, on the other hand, require low-latency responses, often using Spark Streaming or Azure Stream Analytics. Both require error handling, retry mechanisms, and performance tuning.
The orchestration of these pipelines, which includes triggers, dependencies, and monitoring, is a key exam area. Engineers must ensure pipelines run reliably and recover gracefully from failures without compromising data consistency or quality.
Implementing Enterprise-Level Data Security
While technical knowledge is necessary, securing data assets and ensuring compliance is where architecture meets governance. The DP-203 exam evaluates whether candidates can implement data protection at every layer—from ingestion through transformation to serving.
Security begins with identity. Role-based access control must be configured so only authorized users or systems can access sensitive data. Encryption at rest and in transit must be enforced across all services. Network security, using private endpoints and service endpoints, restricts unauthorized access from external sources.
Engineers must be familiar with integrating Key Vault for secrets management, securing storage accounts with shared access signatures, and managing data lake permissions using access control lists. Additionally, they should know how to enforce compliance policies with Azure Purview or integrate classification metadata into data lakes and warehouses.
The exam expects candidates to understand the difference between soft deletes, data masking, and advanced techniques like double encryption. Engineers must prove they can secure streaming data, especially when personal or sensitive information flows through real-time analytics systems.
Security is not a one-time setup. Engineers must architect solutions that adapt to changing threat models, maintain logs for auditing, and apply the principle of least privilege in every data layer.
Monitoring and Optimizing Workloads
No data solution is complete without comprehensive monitoring. Engineers must prove that they can detect bottlenecks, identify cost anomalies, and ensure business SLAs are met through active observability.
Monitoring involves setting up dashboards, alerts, and logs across various services. Azure Monitor and Log Analytics are primary tools for this domain. Candidates should understand how to correlate events, visualize performance trends, and troubleshoot errors using diagnostic settings.
Optimization goes hand-in-hand with monitoring. Engineers must apply cost-saving strategies, such as data lifecycle policies that move infrequently accessed data to cooler storage tiers. In batch processing, parallelism and partition pruning can significantly reduce runtime and cost. For streaming workloads, checkpointing and backpressure mechanisms keep pipelines reliable and responsive.
The DP-203 exam also tests the ability to design for high availability and disaster recovery. This includes understanding geo-replication, failover strategies, and backup automation. Engineers must ensure continuity not just in the event of hardware failure but also during software bugs, schema changes, or human errors.
Applying Azure Data Engineering in the Real World
A distinguishing feature of the DP-203 exam is its emphasis on real-world decision-making. Engineers are expected to design systems that adapt to the changing needs of businesses. This requires combining skills in architecture, development, and operations into a unified data strategy.
Projects often begin with poorly structured or inconsistent data coming from legacy systems, APIs, or manual sources. Engineers must implement ELT pipelines that preserve data integrity while transforming it for analytical use. They are also tasked with creating semantic layers or star schemas that allow analysts to query data without needing to understand complex transformations.
Every data solution must consider cost, scalability, performance, and security from the start. Engineers often make trade-offs between real-time insights and processing cost. They may also be asked to future-proof the architecture by introducing modular components, containerized execution environments, or schema evolution strategies.
Moreover, Azure Data Engineers play a critical role in governance. They work closely with compliance teams to ensure that data access follows legal and ethical guidelines. This may involve implementing auditing mechanisms, lineage tracing, and user behavior analytics.
Collaboration is another key dimension. Azure Data Engineers must frequently interact with data scientists, business analysts, DevOps engineers, and solution architects. Each stakeholder expects clean, well-organized, and trustworthy data. Engineers must structure their solutions so they serve diverse needs without becoming brittle or over-engineered.
The Non-Technical Mindset Behind Data Engineering Success
Although the DP-203 exam is technical in nature, true success lies in adopting a broader mindset. Azure Data Engineers are not just problem-solvers but value creators. They must think in terms of business outcomes, operational excellence, and ethical data use.
For example, implementing a new data warehouse is not just a technical task—it’s about enabling faster, better-informed decisions across an enterprise. When engineers choose a storage solution or data pipeline, they’re balancing cost, speed, accuracy, and risk. Understanding the needs of business units and aligning architecture decisions with strategic goals is what separates good data engineers from great ones.
Documentation and communication also play an underrated role. Well-written documentation, intuitive data models, and clearly defined data contracts help teams onboard quickly and maintain reliability over time. Engineers must also be able to present their solutions to non-technical stakeholders in clear, confident language.
Soft skills such as collaboration, time management, and adaptability become especially important in production environments. Systems will fail, requirements will change, and budgets will shrink. Engineers who can stay calm, learn quickly, and rework their approach without compromising quality are invaluable to any data-driven organization.
Preparing for Success in the DP-203 Exam
A focused preparation strategy involves mastering key technologies and concepts, such as Azure Synapse Analytics, Azure Data Factory, Data Lake Storage, Event Hubs, and SQL Pools. But technical familiarity is only half the journey.
Real preparation involves applying these tools to real use cases. Candidates should build end-to-end projects that simulate real-world environments. These projects should include ingestion from multiple sources, complex transformations, scalable storage designs, monitoring integrations, and role-based security.
Understanding the interaction between services is critical. For instance, how Data Factory pipelines can orchestrate Spark jobs on Synapse, or how Data Lake permissions affect downstream BI access. Engineers should know what failure looks like in each service and how to recover gracefully.
Time management during the exam is also important. The questions are scenario-based and often multi-layered, requiring thoughtful consideration. Rushing through without a clear understanding of the requirements can lead to incorrect assumptions and choices.
Lastly, staying updated with platform changes is crucial. Azure is a rapidly evolving platform, and many features change or get deprecated over time. Engineers must stay informed about new capabilities, best practices, and architectural patterns that enhance efficiency and reliability.
Building an Azure Data Engineer Career: Final Phase of Mastery and Application
Becoming a certified Azure Data Engineer is not merely about passing the DP-203 exam—it is about transforming how organizations manage, optimize, and secure their data. Once the theoretical knowledge is acquired and validated through certification, the real journey begins.
Real-world application of Azure Data Engineering concepts
The true value of the Azure Data Engineer role is demonstrated when theoretical knowledge is turned into reliable solutions. Real-world scenarios demand a high level of flexibility and expertise. Engineers are responsible for creating data environments that function efficiently across structured, semi-structured, and unstructured datasets. These environments are rarely static. Instead, they evolve with new data types, changing business needs, and expanding integration points.
An Azure Data Engineer working in production settings must handle data lake management, metadata-driven pipelines, and event-driven architectures. Building scalable ingestion pipelines using tools like Azure Data Factory or implementing complex transformation logic using Azure Databricks are just foundational tasks. The key lies in operationalizing these workloads through continuous monitoring and automated fault recovery mechanisms.
Enhancing architecture with modular data patterns
An advanced Azure Data Engineer thinks in terms of reusable, decoupled modules. Data ingestion, transformation, cleansing, and serving layers are separated by design. This separation enables plug-and-play components that can evolve independently. In modern cloud solutions, modularity also supports integration with external APIs and real-time data sources.
Designing architectures around micro-batches or real-time events demands a deep understanding of service boundaries, message queuing systems, and stream processing principles. These skills become essential as systems expand and latency, throughput, and cost optimization become more critical. Incorporating these modular designs ensures long-term maintainability and reduced technical debt.
Enabling self-service analytics and data democratization
One of the overlooked responsibilities of Azure Data Engineers is enabling analytics for non-technical stakeholders. Data democratization doesn’t mean dumping all data into a central store. It involves creating governed datasets and semantic layers that business users can understand and explore.
Well-designed serving layers, powered by Synapse or Power BI, allow users to perform ad hoc analysis, generate dashboards, and conduct predictive modeling without involving the data engineering team for every request. This transition requires clear data cataloging, row-level security enforcement, and high-performing curated datasets. It also includes training and documentation so that teams can use these resources with confidence.
Maintaining data systems through lifecycle management
Azure Data Engineers must ensure their systems perform predictably throughout the data lifecycle—from ingestion to archival. Designing lifecycle-aware pipelines involves selecting appropriate storage tiers, enforcing retention policies, and automating data purging for regulatory compliance.
Cold storage of infrequently accessed data, auto-scaling compute for variable workloads, and minimizing I/O costs through partitioning strategies are essential. These decisions must be based on both access frequency and business criticality. A well-structured lifecycle design ensures that data systems are performant, compliant, and cost-effective.
Monitoring and observability in production pipelines
Once systems are in place, maintaining uptime and performance becomes a key priority. Monitoring is not an afterthought—it’s embedded into pipeline design. Azure Monitor, Log Analytics, and custom logging solutions provide visibility into every layer of the data stack.
The role of observability is not limited to detecting failures. Engineers need to implement proactive alerts, usage dashboards, and anomaly detection systems. By visualizing ingestion latencies, transformation bottlenecks, and query response times, teams can make data-driven decisions about scaling and tuning.
Implementing root cause analysis mechanisms and retry strategies in pipelines also improves operational resilience. Failures in upstream services should not propagate errors downstream. These defensive designs form the basis of production-grade systems that can scale with business needs.
Evolving with the Azure ecosystem
The Azure ecosystem is in constant evolution. New services, integrations, and features appear regularly, often requiring rethinking architectural decisions. Staying current requires proactive learning and hands-on experimentation. While certification ensures baseline competence, real advancement comes through staying active in communities, testing preview features, and collaborating with teams across disciplines.
Cloud-native architectures are converging toward hybrid and multi-cloud models. Azure Data Engineers should familiarize themselves with integration patterns across environments. Understanding interoperability between cloud services, managing cross-region replication, and working with hybrid identity and data governance frameworks will be necessary in the coming years.
Strengthening data security and compliance posture
Data protection is a dynamic challenge. Azure Data Engineers must go beyond encryption and access control. They must design architectures where compliance and security are automated. Implementing Azure Purview for metadata management, enforcing data classification at ingestion, and building policy-driven access models with role-based or attribute-based controls becomes crucial.
As privacy regulations evolve, engineers must ensure that data lineage is traceable, audit logs are immutable, and retention rules are strictly followed. Combining sensitivity labels, tokenization, and pseudonymization allows for broader data usage without violating privacy standards. These advanced security strategies distinguish engineers who design reactive systems from those who lead proactive governance models.
Developing leadership and cross-functional collaboration
A senior-level Azure Data Engineer’s role increasingly overlaps with architecture and strategic planning. Effective engineers must work closely with data scientists, product owners, governance teams, and security professionals. The ability to explain technical choices in business terms is critical.
This role includes mentoring junior engineers, designing onboarding processes, and setting coding standards. Code reviews, technical documentation, and knowledge-sharing sessions help elevate team maturity. The engineer becomes not just a contributor, but also a culture shaper—someone who drives best practices and quality across the organization.
Participating in architectural review boards, leading design discussions, and proposing platform-level improvements signal a shift from execution to influence. This progression aligns with the increasing importance of data in digital transformation strategies.
Preparing for long-term growth in data engineering
The path beyond certification is shaped by continuous growth and reinvention. Azure Data Engineers looking to grow in their careers can pursue specialized domains like streaming analytics, AI-powered data processing, or data governance strategy. These domains open doors to emerging roles such as machine learning engineer, data platform architect, and data governance consultant.
Building open-source contributions, writing about project insights, and speaking at internal or external events not only solidify knowledge but also grow visibility. These efforts distinguish professionals in a competitive landscape.
Additionally, engineers should embrace challenges such as designing for global scale, implementing disaster recovery, or supporting data monetization strategies. Each challenge reinforces skills and expands horizons.
Conclusion:
The DP-203 certification serves as the entry point into a transformative career. But true value is unlocked through application, adaptability, and continuous learning. Azure Data Engineers who move beyond isolated pipeline development to platform thinking, governance-driven design, and cross-functional leadership stand out in every organization.
Their impact is not just measured in the volume of data processed, but in how effectively that data empowers decision-making, improves services, and drives innovation. Through disciplined architecture, intelligent automation, and an unwavering focus on data quality and security, they help shape data-driven cultures that thrive on clarity, integrity, and agility.
In a world increasingly defined by data, these professionals hold the blueprint for how information flows, scales, and transforms entire industries. The journey doesn’t end with certification—it starts with it. The foundation built through DP-203 is the platform on which careers are launched, organizations are strengthened, and futures are engineered.
Pass your Microsoft Azure DP-203 certification exam with the latest Microsoft Azure DP-203 practice test questions and answers. Total exam prep solutions provide shortcut for passing the exam by using DP-203 Microsoft Azure certification practice test questions and answers, exam dumps, video training course and study guide.
-
Microsoft Azure DP-203 practice test questions and Answers, Microsoft Azure DP-203 Exam Dumps
Got questions about Microsoft Azure DP-203 exam dumps, Microsoft Azure DP-203 practice test questions?
Click Here to Read FAQ -
-
Top Microsoft Exams
- AZ-104 - Microsoft Azure Administrator
- AZ-305 - Designing Microsoft Azure Infrastructure Solutions
- SC-300 - Microsoft Identity and Access Administrator
- AB-100 - Agentic AI Business Solutions Architect
- AI-103 - Developing AI Apps and Agents on Azure
- DP-700 - Implementing Data Engineering Solutions Using Microsoft Fabric
- MD-102 - Endpoint Administrator
- PL-300 - Microsoft Power BI Data Analyst
- AB-900 - Microsoft 365 Copilot and Agent Administration Fundamentals
- SC-200 - Microsoft Security Operations Analyst
- SC-401 - Administering Information Security in Microsoft 365
- AZ-900 - Microsoft Azure Fundamentals
- MS-102 - Microsoft 365 Administrator
- DP-600 - Implementing Analytics Solutions Using Microsoft Fabric
- SC-100 - Microsoft Cybersecurity Architect
- AZ-700 - Designing and Implementing Microsoft Azure Networking Solutions
- AI-900 - Microsoft Azure AI Fundamentals
- AZ-500 - Microsoft Azure Security Technologies
- AB-731 - AI Transformation Leader
- AB-730 - AI Business Professional
- GH-300 - GitHub Copilot
- AI-102 - Designing and Implementing a Microsoft Azure AI Solution
- PL-400 - Microsoft Power Platform Developer
- AZ-400 - Designing and Implementing Microsoft DevOps Solutions
- AZ-204 - Developing Solutions for Microsoft Azure
- DP-300 - Administering Microsoft Azure SQL Solutions
- AZ-140 - Configuring and Operating Microsoft Azure Virtual Desktop
- SC-900 - Microsoft Security, Compliance, and Identity Fundamentals
- AZ-801 - Configuring Windows Server Hybrid Advanced Services
- AI-901 - Microsoft Azure AI Fundamentals
- SC-500 - Implementing End-to-End Security Controls for Cloud and AI Workloads
- AI-300 - Operationalizing Machine Learning and Generative AI Solutions
- MS-700 - Managing Microsoft Teams
- PL-900 - Microsoft Power Platform Fundamentals
- AZ-800 - Administering Windows Server Hybrid Core Infrastructure
- DP-800 - Developing AI-Enabled Database Solutions
- PL-200 - Microsoft Power Platform Functional Consultant
- PL-600 - Microsoft Power Platform Solution Architect
- MB-800 - Microsoft Dynamics 365 Business Central Functional Consultant
- MB-310 - Microsoft Dynamics 365 Finance Functional Consultant
- AB-620 - Designing and Building Integrated AI Agent Solutions in Copilot Studio
- MB-330 - Microsoft Dynamics 365 Supply Chain Management
- DP-900 - Microsoft Azure Data Fundamentals
- DP-750 - Implementing Data Engineering Solutions Using Azure Databricks
- MB-820 - Microsoft Dynamics 365 Business Central Developer
- MB-230 - Microsoft Dynamics 365 Customer Service Functional Consultant
- MB-280 - Microsoft Dynamics 365 Customer Experience Analyst
- MS-721 - Collaboration Communications Systems Engineer
- GH-900 - GitHub Foundations
- AB-410 - Building Intelligent Applications
- GH-200 - GitHub Actions
- MB-700 - Microsoft Dynamics 365: Finance and Operations Apps Solution Architect
- MB-500 - Microsoft Dynamics 365: Finance and Operations Apps Developer
- DP-420 - Designing and Implementing Cloud-Native Applications Using Microsoft Azure Cosmos DB
- PL-500 - Microsoft Power Automate RPA Developer
- GH-500 - GitHub Advanced Security
- GH-100 - GitHub Administration
- MB-335 - Microsoft Dynamics 365 Supply Chain Management Functional Consultant Expert
- AI-200 - Developing AI Cloud Solutions on Azure
- MS-900 - Microsoft 365 Fundamentals
- MB-240 - Microsoft Dynamics 365 for Field Service
- SC-400 - Microsoft Information Protection Administrator
- AZ-120 - Planning and Administering Microsoft Azure for SAP Workloads
- DP-100 - Designing and Implementing a Data Science Solution on Azure
- MS-203 - Microsoft 365 Messaging
- MO-400 - Microsoft Outlook (Outlook and Outlook 2019)
- GH-600 - Developing in Agentic AI Systems
- 62-193 - Technology Literacy for Educators
-
Purchase Microsoft DP-203 Exam Training Products Individually
Last Week Results!
Get PDF Version of DP-203 Questions & Answers
With the PDF Version of the exam questions, you can study at any time and place, which are convenient to you. This means that you can work with the DP-203 Questions & Answers PDF Version on your PC or use it on your portable device while on the way to your work or home. The PDF exam file also offers you the possibility to print it and use this printed version if you prefer it over the digital one.
Since the file is in the .pdf format, you can open it with a wide range of programs and applications, including Google Docs, OpenOffice, and Adobe Acrobat Reader DC. It is a convenient and easy-to-use option that will help you master new knowledge and skills with relevant materials.
* PDF Version is an add-on to your purchase of DP-203 Questions & Answers and can't be purchased separately.
Only Registered Members can Download Exam Demo Questions & Answers
Please fill out your email address below in order to exam demo Questions & Answers.
Registration is Free and Easy, You Simply need to provide a valid email address.
- Trusted by hundreds of IT Certification Candidates Every Month
- 1200+ Exams Available
- Instant download After Registration