Microsoft Microsoft Certified: Azure Data Engineer Associate
- Exam: DP-203 (Data Engineering on Microsoft Azure)
- Certification: Microsoft Certified: Azure Data Engineer Associate
- Certification Provider: Microsoft

100% Updated Microsoft Microsoft Certified: Azure Data Engineer Associate Certification DP-203 Exam Dumps
Microsoft Microsoft Certified: Azure Data Engineer Associate DP-203 Practice Test Questions, Microsoft Certified: Azure Data Engineer Associate Exam Dumps, Verified Answers
-
-

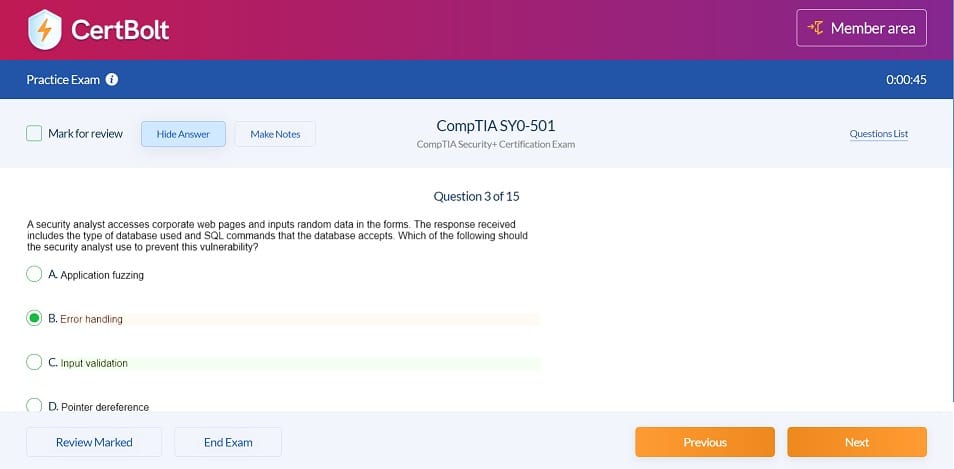
DP-203 Questions & Answers
397 Questions & Answers
Includes 100% Updated DP-203 exam questions types found on exam such as drag and drop, simulation, type in, and fill in the blank. Fast updates, accurate answers for Microsoft Microsoft Certified: Azure Data Engineer Associate DP-203 exam. Exam Simulator Included!
-

DP-203 Online Training Course
262 Video Lectures
Learn from Top Industry Professionals who provide detailed video lectures based on 100% Latest Scenarios which you will encounter in exam.
-

DP-203 Study Guide
1325 PDF Pages
Study Guide developed by industry experts who have written exams in the past. Covers in-depth knowledge which includes Entire Exam Blueprint.
-
-
Microsoft Microsoft Certified: Azure Data Engineer Associate Certification Practice Test Questions, Microsoft Microsoft Certified: Azure Data Engineer Associate Certification Exam Dumps
Latest Microsoft Microsoft Certified: Azure Data Engineer Associate Certification Practice Test Questions & Exam Dumps for Studying. Cram Your Way to Pass with 100% Accurate Microsoft Microsoft Certified: Azure Data Engineer Associate Certification Exam Dumps Questions & Answers. Verified By IT Experts for Providing the 100% Accurate Microsoft Microsoft Certified: Azure Data Engineer Associate Exam Dumps & Microsoft Microsoft Certified: Azure Data Engineer Associate Certification Practice Test Questions.
Microsoft Certified: Azure Data Engineer Associate Certification – Your Gateway to Data Engineering Excellence
The Microsoft Certified Azure Data Engineer Associate credential validates a professional's ability to design and implement data management, monitoring, security, and privacy solutions using the full range of Azure data services. It targets practitioners who are responsible for integrating, transforming, and consolidating data from various structured and unstructured data systems into structures suitable for building analytics solutions that support organizational decision-making at scale.
This certification has become one of the most sought-after credentials in the data engineering profession because it aligns directly with the skills that organizations need as they migrate on-premises data infrastructure to cloud-based platforms and build modern data pipelines capable of handling the volume, velocity, and variety of data generated by contemporary business operations. Employers across financial services, healthcare, retail, manufacturing, and technology sectors consistently list Azure data engineering skills among their most critical hiring priorities for technical data roles.
Target Audience for This Credential
The Azure Data Engineer Associate certification is designed for professionals who work at the intersection of data infrastructure and analytics, including data engineers, data architects, database administrators transitioning to cloud platforms, and software engineers who have taken on data pipeline responsibilities within their organizations. The ideal candidate has solid experience with data processing languages including SQL and Python, familiarity with cloud computing concepts, and practical exposure to at least some Azure data services before attempting the certification exam.
Business intelligence developers who want to expand their skill set beyond reporting and visualization into the underlying data engineering layer that feeds analytical workloads also find this certification a natural progression from their existing expertise. Similarly, on-premises database professionals who have worked extensively with SQL Server, Oracle, or other relational database platforms and are now being asked to lead or contribute to cloud migration initiatives benefit from the structured framework the certification provides for building Azure-specific data engineering competency alongside their existing relational data management knowledge.
Exam Structure and Format Details
The Azure Data Engineer Associate certification requires passing a single exam, currently designated DP-203, which covers the design and implementation of data storage, data processing, and data security solutions using Azure services. The exam consists of between forty and sixty questions delivered over one hundred twenty minutes, with question types including multiple choice, multiple select, case studies, drag and drop, and ordering questions that reflect the multi-step reasoning required to solve real data engineering problems.
Microsoft periodically updates the DP-203 exam to reflect changes in Azure services and evolving data engineering practices, so candidates should always verify the current exam objectives published on the official Microsoft Learn certification page before beginning their preparation. The passing score for the exam is seven hundred out of one thousand, and results are available immediately upon completion of the testing session at a Pearson VUE center or through an online proctored format. Candidates who do not pass on the first attempt may retake the exam after a waiting period of twenty-four hours for the first retake, with progressively longer waiting periods required for subsequent attempts.
Core Skills and Knowledge Areas
The DP-203 exam covers four primary skill domains that reflect the end-to-end responsibilities of an Azure data engineer in a production environment. These domains are designing and implementing data storage solutions, designing and developing data processing solutions, designing and implementing data security, and monitoring and optimizing data storage and data processing. Each domain is weighted differently in the exam, with data storage and data processing together accounting for the majority of scored content.
Within these domains, candidates are expected to demonstrate practical knowledge of how to select appropriate Azure data services for specific data engineering requirements, configure those services correctly, integrate them into coherent data pipeline architectures, and optimize them for performance and cost efficiency. The exam does not test superficial familiarity with service names and marketing descriptions but rather the ability to apply service knowledge to realistic engineering scenarios where multiple technically valid options exist and the candidate must identify the approach that best meets the stated requirements and constraints.
Azure Storage Services Knowledge
A deep understanding of Azure storage services is foundational to data engineering on the Azure platform, and it represents one of the most heavily tested areas in the DP-203 exam. Candidates must be thoroughly familiar with Azure Data Lake Storage Gen2, which combines the hierarchical namespace capabilities of a traditional file system with the scale and cost efficiency of Azure Blob Storage, making it the preferred storage layer for big data analytics workloads on Azure.
Beyond Data Lake Storage Gen2, candidates should understand Azure Blob Storage tiers and their cost implications, Azure Files for shared file system scenarios, and the use of storage access controls including shared access signatures, stored access policies, and Azure Active Directory-based role assignments for securing data at rest. The ability to design a data lake storage structure that organizes data into raw, curated, and enriched zones while applying appropriate access controls at the folder and file level is a practical skill that the exam tests through scenario-based questions requiring candidates to evaluate proposed storage architectures against stated security and performance requirements.
Azure Synapse Analytics Deep Dive
Azure Synapse Analytics is the most comprehensively tested individual service in the DP-203 exam, reflecting its central role as an integrated analytics platform that combines data warehousing, big data processing, data integration, and exploratory data analysis capabilities within a single unified service. Candidates must understand the full range of Synapse capabilities including dedicated SQL pools for data warehousing workloads, serverless SQL pools for on-demand querying of data in the data lake, Apache Spark pools for large-scale data transformation and machine learning workloads, and Synapse Pipelines for data integration and orchestration.
The exam tests candidates on specific configuration decisions within Synapse, including the selection of appropriate distribution strategies for dedicated SQL pool tables such as hash distribution, round-robin distribution, and replicated tables, the design of appropriate indexing strategies including clustered columnstore indexes and heap tables for staging scenarios, and the optimization of query performance through statistics management, result set caching, and workload management configuration. Candidates who approach Synapse preparation by understanding why each configuration option exists and what performance or cost problem it solves will be far better equipped to answer scenario-based questions than those who memorize configuration steps without understanding the underlying rationale.
Azure Data Factory Pipeline Design
Azure Data Factory is the primary data integration and orchestration service on the Azure platform, enabling engineers to build automated pipelines that ingest data from hundreds of source systems, transform it through a visual dataflow designer or external compute services, and load it into analytical destinations. The DP-203 exam covers Data Factory extensively, testing candidates on pipeline design, activity configuration, trigger types, integration runtime options, and monitoring and troubleshooting of pipeline execution.
Key Data Factory concepts that candidates must understand include the difference between the Azure integration runtime for cloud-based data movement, the self-hosted integration runtime for on-premises and private network data sources, and the Azure-SSIS integration runtime for lifting and shifting existing SQL Server Integration Services packages to the cloud. Candidates should also be comfortable with the mapping data flow capability within Data Factory, which provides a code-free transformation environment that generates Apache Spark code under the covers and supports a wide range of data transformation operations that can be visually composed and debugged without writing Spark code directly.
Stream Processing and Real-Time Data
Real-time data processing is a growing component of modern data engineering workloads, and the DP-203 exam dedicates meaningful attention to the Azure services used to ingest, process, and analyze streaming data. The primary streaming ingestion service covered on the exam is Azure Event Hubs, a fully managed event streaming platform capable of ingesting millions of events per second from diverse sources including IoT devices, application telemetry, and clickstream data generators.
Azure Stream Analytics is the primary service tested for real-time stream processing, providing a fully managed SQL-based query engine that can read from Event Hubs, Azure IoT Hub, and Azure Blob Storage inputs, apply windowing functions and complex event processing logic, and write results to a wide range of output destinations including Azure SQL Database, Cosmos DB, Power BI, and Data Lake Storage. Candidates should understand the different window types available in Stream Analytics including tumbling, hopping, sliding, and session windows, as well as the configuration of streaming units for scaling Stream Analytics jobs to meet throughput requirements and the use of reference data joins for enriching streaming events with relatively static dimensional data.
Azure Databricks for Data Engineering
Azure Databricks is a fully managed Apache Spark platform optimized for collaborative data engineering and machine learning workloads on Azure, and it appears prominently in the DP-203 exam as a key service for large-scale data transformation, feature engineering, and advanced analytics pipeline development. Candidates should understand the Databricks workspace architecture, cluster configuration options including interactive clusters for development and job clusters for production workloads, and the use of Databricks notebooks for collaborative development of Spark-based data transformation logic.
The exam tests candidates on the use of Delta Lake within Databricks, which is an open-source storage layer that adds ACID transaction support, schema enforcement, and time travel capabilities to data lake storage, addressing the reliability and consistency challenges that arise when multiple concurrent processes read from and write to shared data lake locations. Understanding how to implement a Delta Lake architecture within Databricks, including the use of merge operations for upsert scenarios, the management of Delta table history for auditing and rollback purposes, and the optimization of Delta tables through vacuum and optimize commands, is essential for performing well on the Databricks-related content in the DP-203 exam.
Data Security and Governance Requirements
Data security is one of the four primary domains in the DP-203 exam and covers the range of controls and configurations that data engineers must implement to protect sensitive data throughout its lifecycle in Azure data environments. Candidates must understand encryption at rest and in transit for each major Azure data service, the configuration of network security controls including virtual network service endpoints, private endpoints, and firewall rules that restrict access to data services from specific network locations.
Row-level security and column-level security in Azure Synapse dedicated SQL pools are specific security features that the exam tests, covering the implementation of security predicates that filter data rows based on the identity of the querying user and the use of column masking functions that obscure sensitive column values for users who do not have permissions to view them in clear text. Microsoft Purview, the Azure data governance service, is also covered in the exam context of data cataloging, data classification, and data lineage tracking, which are governance capabilities that organizations increasingly require as regulatory frameworks like GDPR and CCPA impose stricter requirements on data management practices.
Performance Optimization Strategies
Performance optimization is tested extensively throughout the DP-203 exam because data engineers are expected not only to build functional data pipelines but to ensure that those pipelines and the data stores they feed operate efficiently enough to meet the service level agreements that business users depend upon for timely access to analytical data. In Azure Synapse dedicated SQL pools, performance optimization involves selecting appropriate table distribution strategies, designing effective indexing approaches, managing statistics to support accurate query plan generation, and configuring result set caching for frequently executed queries against stable data.
In Azure Data Lake Storage, performance optimization involves understanding the impact of file size and format on query performance, with columnar formats like Apache Parquet and ORC providing significantly better analytical query performance than row-based formats like CSV and JSON for large datasets. Partitioning strategies that align with common query filter patterns reduce the volume of data that must be scanned for typical analytical queries, and candidates should be able to evaluate proposed partitioning designs against described query patterns and identify whether the proposed design would provide effective partition pruning for the stated workload.
Monitoring and Troubleshooting Pipelines
The ability to monitor data pipeline execution and troubleshoot failures effectively is a practical skill that the DP-203 exam tests through scenario questions describing pipeline failures, performance degradations, or unexpected data quality issues and requiring candidates to identify the appropriate diagnostic approach and corrective action. Azure Monitor, Azure Data Factory monitoring, and Synapse Analytics monitoring tools each provide different views into the health and performance of data engineering workloads, and candidates should understand what information each tool provides and when each is most appropriately used.
Common troubleshooting scenarios on the exam include Data Factory pipeline activities that fail due to connectivity issues with source or destination systems, Synapse dedicated SQL pool queries that execute more slowly than expected due to data skew or missing statistics, and Stream Analytics jobs that fall behind in processing their input stream due to insufficient streaming unit allocation. Candidates who have worked through these types of issues in real Azure environments will recognize them immediately in exam scenarios, while those who have only studied conceptually may struggle to identify the specific root causes and remediation steps that the exam expects them to know.
Study Resources and Learning Paths
Microsoft Learn provides a comprehensive and freely available learning path for the DP-203 exam that covers all exam objective areas through a combination of conceptual modules, hands-on exercises, and knowledge check assessments. This official learning path is the most directly aligned free resource available and should form the backbone of any preparation plan, supplemented by additional resources that provide deeper technical depth or alternative explanations for concepts that candidates find challenging after initial exposure.
Beyond Microsoft Learn, several high-quality paid preparation resources are available including video courses from Udemy instructors such as Ramesh Retnasamy and Alan Rodrigues, whose DP-203 courses are frequently recommended by candidates in Azure data engineering community forums. Practice exams from providers like MeasureUp, Whizlabs, and ExamTopics allow candidates to assess their readiness and identify specific knowledge gaps before the actual exam. Hands-on practice using the Azure free tier and pay-as-you-go services for lab exercises is essential, and most candidates who pass the exam on their first attempt cite regular hands-on practice as the most important factor in their preparation success.
Hands-On Lab Practice Approach
Theoretical knowledge of Azure data services is necessary but not sufficient for passing the DP-203 exam or performing effectively as an Azure data engineer in a production environment. Regular hands-on practice that involves actually provisioning, configuring, and using Azure data services to complete realistic data engineering tasks builds the intuitive service knowledge that makes scenario-based exam questions straightforward rather than challenging.
A structured lab practice approach for DP-203 preparation might involve building an end-to-end data pipeline that ingests raw data from a simulated source system using Azure Data Factory, stores it in Azure Data Lake Storage Gen2 with appropriate folder structure and access controls, transforms it using either mapping data flows in Data Factory or notebooks in Azure Databricks, loads the transformed data into an Azure Synapse Analytics dedicated SQL pool with an appropriate distribution and indexing strategy, and makes it available for analysis through a serverless SQL pool view. Working through this type of end-to-end scenario multiple times with different source data types, transformation requirements, and security constraints builds the breadth and depth of practical knowledge that the exam rewards and that professional data engineering roles demand.
Conclusion
The Microsoft Certified Azure Data Engineer Associate certification represents one of the most professionally valuable credentials available to data practitioners who want to build or validate expertise in cloud-based data engineering on the Azure platform, and the preparation journey toward earning it provides a structured curriculum for developing the technical depth that modern data engineering roles genuinely require. Throughout this guide, the certification's target audience, exam structure, technical content domains, service-level knowledge requirements, security and governance coverage, performance optimization skills, monitoring capabilities, and preparation resources have all been examined in detail to give aspiring and current data engineering professionals a comprehensive understanding of what the certification demands and how to meet those demands effectively.
The data engineering profession is experiencing sustained and significant growth as organizations across every industry recognize that their ability to compete effectively depends on their capacity to collect, process, store, and analyze data at scale and with sufficient speed to support real-time and near-real-time decision-making. Azure has established itself as one of the two or three dominant cloud platforms for enterprise data workloads, and professionals who can demonstrate verified competency in designing and implementing data engineering solutions on Azure are positioned at the center of this demand with strong negotiating leverage in the job market and clear pathways to continued career advancement.
The technical breadth required by the DP-203 exam reflects the genuine breadth of skills that a practicing Azure data engineer must command, spanning storage architecture design, pipeline development and orchestration, stream processing, big data transformation, data warehouse optimization, security control implementation, and operational monitoring. Candidates who approach preparation with the goal of genuinely developing these skills rather than simply passing an exam will emerge from the experience as meaningfully more capable data engineering professionals, not just as credential holders, and that genuine capability development is what produces the long-term career returns that make this certification worth pursuing.
For professionals who pass the DP-203 and are considering where to invest their next certification effort, several natural progressions exist depending on career interests and organizational needs. The Microsoft Certified Azure Solutions Architect Expert credential broadens the scope from data engineering specifically to overall Azure architecture design, while the Databricks Certified Data Engineer Professional credential provides deeper specialization in the Spark-based data engineering workflows that are increasingly central to large-scale data platform architectures. Data professionals with interests in machine learning and artificial intelligence can build naturally from Azure data engineering expertise toward the Microsoft Certified Azure Data Scientist Associate credential, which covers the design and implementation of machine learning solutions that consume the data pipelines and feature stores that data engineers build and maintain.
Regardless of which direction the career path leads beyond this certification, the foundation built through thorough Azure Data Engineer Associate preparation — combining conceptual understanding of data engineering principles with practical hands-on experience across the Azure data service portfolio — will remain a durable professional asset in a field where the underlying platforms continue to evolve but the core engineering disciplines of data ingestion, transformation, storage, and delivery remain constant and consistently valued by the organizations that depend on data-driven decision-making for their competitive success.
Pass your next exam with Microsoft Microsoft Certified: Azure Data Engineer Associate certification exam dumps, practice test questions and answers, study guide, video training course. Pass hassle free and prepare with Certbolt which provide the students with shortcut to pass by using Microsoft Microsoft Certified: Azure Data Engineer Associate certification exam dumps, practice test questions and answers, video training course & study guide.
-
Microsoft Microsoft Certified: Azure Data Engineer Associate Certification Exam Dumps, Microsoft Microsoft Certified: Azure Data Engineer Associate Practice Test Questions And Answers
Got questions about Microsoft Microsoft Certified: Azure Data Engineer Associate exam dumps, Microsoft Microsoft Certified: Azure Data Engineer Associate practice test questions?
Click Here to Read FAQ -
-
Top Microsoft Exams
- AZ-104 - Microsoft Azure Administrator
- AZ-305 - Designing Microsoft Azure Infrastructure Solutions
- AI-103 - Developing AI Apps and Agents on Azure
- AB-100 - Agentic AI Business Solutions Architect
- SC-300 - Microsoft Identity and Access Administrator
- DP-700 - Implementing Data Engineering Solutions Using Microsoft Fabric
- PL-300 - Microsoft Power BI Data Analyst
- AB-900 - Microsoft 365 Copilot and Agent Administration Fundamentals
- MD-102 - Endpoint Administrator
- SC-200 - Microsoft Security Operations Analyst
- AZ-900 - Microsoft Azure Fundamentals
- SC-401 - Administering Information Security in Microsoft 365
- MS-102 - Microsoft 365 Administrator
- DP-600 - Implementing Analytics Solutions Using Microsoft Fabric
- SC-100 - Microsoft Cybersecurity Architect
- AZ-700 - Designing and Implementing Microsoft Azure Networking Solutions
- AZ-500 - Microsoft Azure Security Technologies
- AI-900 - Microsoft Azure AI Fundamentals
- AB-731 - AI Transformation Leader
- AB-730 - AI Business Professional
- GH-300 - GitHub Copilot
- AI-102 - Designing and Implementing a Microsoft Azure AI Solution
- PL-400 - Microsoft Power Platform Developer
- AZ-400 - Designing and Implementing Microsoft DevOps Solutions
- AZ-204 - Developing Solutions for Microsoft Azure
- AZ-140 - Configuring and Operating Microsoft Azure Virtual Desktop
- DP-300 - Administering Microsoft Azure SQL Solutions
- AI-901 - Microsoft Azure AI Fundamentals
- SC-900 - Microsoft Security, Compliance, and Identity Fundamentals
- SC-500 - Implementing End-to-End Security Controls for Cloud and AI Workloads
- AZ-801 - Configuring Windows Server Hybrid Advanced Services
- AI-300 - Operationalizing Machine Learning and Generative AI Solutions
- MS-700 - Managing Microsoft Teams
- DP-800 - Developing AI-Enabled Database Solutions
- PL-900 - Microsoft Power Platform Fundamentals
- AZ-800 - Administering Windows Server Hybrid Core Infrastructure
- PL-200 - Microsoft Power Platform Functional Consultant
- PL-600 - Microsoft Power Platform Solution Architect
- AB-620 - Designing and Building Integrated AI Agent Solutions in Copilot Studio
- DP-750 - Implementing Data Engineering Solutions Using Azure Databricks
- MB-310 - Microsoft Dynamics 365 Finance Functional Consultant
- MB-800 - Microsoft Dynamics 365 Business Central Functional Consultant
- DP-900 - Microsoft Azure Data Fundamentals
- MB-330 - Microsoft Dynamics 365 Supply Chain Management
- MB-820 - Microsoft Dynamics 365 Business Central Developer
- MB-230 - Microsoft Dynamics 365 Customer Service Functional Consultant
- MS-721 - Collaboration Communications Systems Engineer
- MB-280 - Microsoft Dynamics 365 Customer Experience Analyst
- AB-410 - Building Intelligent Applications
- GH-900 - GitHub Foundations
- MB-500 - Microsoft Dynamics 365: Finance and Operations Apps Developer
- GH-200 - GitHub Actions
- DP-420 - Designing and Implementing Cloud-Native Applications Using Microsoft Azure Cosmos DB
- MB-700 - Microsoft Dynamics 365: Finance and Operations Apps Solution Architect
- PL-500 - Microsoft Power Automate RPA Developer
- GH-100 - GitHub Administration
- GH-500 - GitHub Advanced Security
- MB-335 - Microsoft Dynamics 365 Supply Chain Management Functional Consultant Expert
- AI-200 - Developing AI Cloud Solutions on Azure
- MS-900 - Microsoft 365 Fundamentals
- MB-240 - Microsoft Dynamics 365 for Field Service
- SC-400 - Microsoft Information Protection Administrator
- AZ-120 - Planning and Administering Microsoft Azure for SAP Workloads
- GH-600 - Developing in Agentic AI Systems
- DP-100 - Designing and Implementing a Data Science Solution on Azure
- MO-400 - Microsoft Outlook (Outlook and Outlook 2019)
- MS-203 - Microsoft 365 Messaging
- 62-193 - Technology Literacy for Educators
-
Purchase Microsoft DP-203 Exam Training Products Individually
Last Week Results!
Get Questions & Answers PDF Version
With the PDF Version of the exam questions, you can study at any time and place, which are convenient to you. This means that you can work with the Microsoft Certified: Azure Data Engineer Associate Questions & Answers PDF Version on your PC or use it on your portable device while on the way to your work or home. The PDF exam file also offers you the possibility to print it and use this printed version if you prefer it over the digital one.
Since the file is in the .pdf format, you can open it with a wide range of programs and applications, including Google Docs, OpenOffice, and Adobe Acrobat Reader DC. It is a convenient and easy-to-use option that will help you master new knowledge and skills with relevant materials.
* PDF Version is an add-on to your purchase of Microsoft Certified: Azure Data Engineer Associate Questions & Answers and can't be purchased separately.
Only Registered Members can Download Exam Demo Questions & Answers
Please fill out your email address below in order to download exam demo Questions & Answers.
Registration is Free and Easy, You Simply need to provide a valid email address.
- Trusted by hundreds of IT Certification Candidates Every Month
- 1200+ Exams Available
- Instant download After Registration