Amazon AWS Certified Machine Learning Engineer - Associate MLA-C01 Bundle
- Exam: AWS Certified Machine Learning Engineer - Associate MLA-C01
- Exam Provider: Amazon

Latest Amazon AWS Certified Machine Learning Engineer - Associate MLA-C01 Exam Dumps Questions
Amazon AWS Certified Machine Learning Engineer - Associate MLA-C01 Exam Dumps, practice test questions, Verified Answers, Fast Updates!
-
-

AWS Certified Machine Learning Engineer - Associate MLA-C01 Questions & Answers
270 Questions & Answers
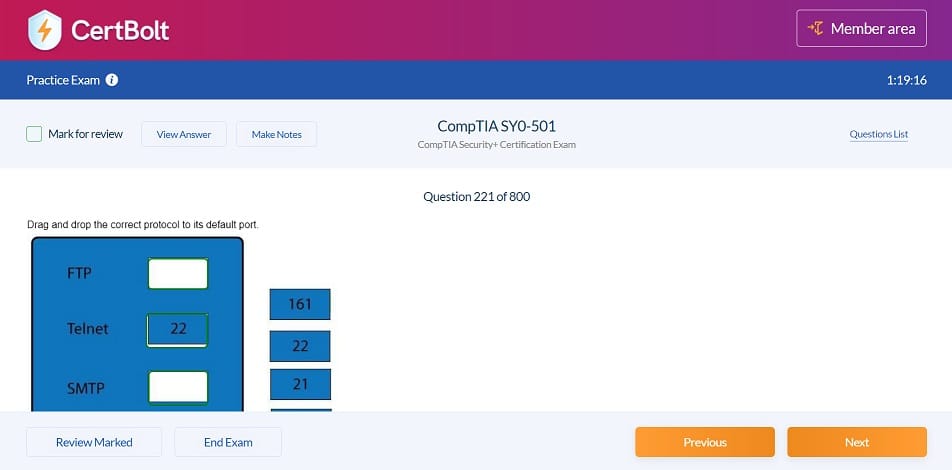
Includes 100% Updated AWS Certified Machine Learning Engineer - Associate MLA-C01 exam questions types found on exam such as drag and drop, simulation, type in, and fill in the blank. Fast updates, accurate answers for Amazon AWS Certified Machine Learning Engineer - Associate MLA-C01 exam. Exam Simulator Included!
-

AWS Certified Machine Learning Engineer - Associate MLA-C01 Study Guide
548 PDF Pages
Study Guide developed by industry experts who have written exams in the past. Covers in-depth knowledge which includes Entire Exam Blueprint.
-
-
Amazon AWS Certified Machine Learning Engineer - Associate MLA-C01 Exam Dumps, Amazon AWS Certified Machine Learning Engineer - Associate MLA-C01 practice test questions
100% accurate & updated Amazon certification AWS Certified Machine Learning Engineer - Associate MLA-C01 practice test questions & exam dumps for preparing. Study your way to pass with accurate Amazon AWS Certified Machine Learning Engineer - Associate MLA-C01 Exam Dumps questions & answers. Verified by Amazon experts with 20+ years of experience to create these accurate Amazon AWS Certified Machine Learning Engineer - Associate MLA-C01 dumps & practice test exam questions. All the resources available for Certbolt AWS Certified Machine Learning Engineer - Associate MLA-C01 Amazon certification practice test questions and answers, exam dumps, study guide, video training course provides a complete package for your exam prep needs.
From Beginner to Pro: Cracking the MLA-C01 Certification
A Machine Learning Engineer certified with the AWS MLA-C01 certification is expected to bridge the gap between theoretical machine learning concepts and their practical deployment on cloud infrastructure. Unlike traditional data scientists who focus primarily on model development, AWS machine learning engineers are responsible for the full lifecycle of a machine learning solution. This includes understanding business requirements, preparing data, selecting appropriate algorithms, training models, optimizing them, deploying them in scalable environments, and monitoring their performance. The role demands not only programming expertise but also deep knowledge of AWS services such as SageMaker, Lambda, Step Functions, and EC2 instances that can handle large-scale data processing.
The certification emphasizes practical application, requiring candidates to demonstrate the ability to operationalize machine learning solutions efficiently. This involves ensuring that models are not just accurate but also robust, secure, and cost-effective. Engineers must understand how to handle data pipelines, implement model versioning, and manage automated retraining workflows. Furthermore, they must be skilled at integrating machine learning endpoints into larger applications, ensuring low latency and high availability.
Core Knowledge Areas For The Certification
The AWS MLA-C01 exam assesses several critical domains that together form the foundation of an effective machine learning engineer’s skill set. Candidates must have a thorough understanding of data engineering principles. This includes cleaning, transforming, and structuring datasets suitable for training machine learning models. It’s essential to know how to leverage AWS services like AWS Glue, Amazon S3, and Athena to process and query data efficiently.
Another fundamental area is modeling. This involves selecting the appropriate machine learning or deep learning algorithm for a given problem. Candidates are expected to understand supervised, unsupervised, and reinforcement learning approaches and the scenarios where each is most effective. For instance, classification problems such as fraud detection require different strategies compared to regression problems like demand forecasting. Engineers must also be aware of the trade-offs in model complexity, interpretability, and computational costs.
Deployment and operations form another critical area. It’s one thing to train a model successfully; it’s another to deploy it in production, monitor its performance, and update it as data patterns evolve. AWS SageMaker provides capabilities like model endpoints, batch transform jobs, and multi-model endpoints that help streamline these tasks. Understanding monitoring metrics, logging, and alerting mechanisms is crucial to ensure that deployed models maintain accuracy and performance over time.
Data Preparation And Feature Engineering
Data is the backbone of any machine learning model. Without quality data, even the most sophisticated algorithms cannot perform well. Machine learning engineers must be adept at gathering data from various sources, identifying inconsistencies, and performing transformations that make it suitable for training. This often includes handling missing values, encoding categorical variables, normalizing numerical features, and detecting outliers. Feature engineering, which involves creating meaningful variables from raw data, is especially critical because it can significantly improve model performance.
AWS offers tools that simplify these processes. For example, SageMaker Data Wrangler allows engineers to clean and prepare data visually, reducing the need for extensive coding. Automated feature selection and transformation can also save time while ensuring that models focus on the most relevant aspects of the data. Understanding when to use feature scaling techniques, dimensionality reduction, and embedding representations for complex data types is vital for success in both the exam and real-world applications.
Choosing The Right Algorithm And Model Evaluation
Selecting the appropriate algorithm is a balance between problem requirements, dataset characteristics, and computational constraints. AWS MLA-C01 candidates must demonstrate proficiency in evaluating model performance using metrics appropriate to the task. For classification tasks, metrics such as accuracy, precision, recall, F1 score, and area under the ROC curve are essential. For regression, metrics like mean squared error, root mean squared error, and mean absolute error provide insights into model performance. Cross-validation techniques are also important to ensure that models generalize well to unseen data.
Understanding algorithmic strengths and limitations is part of this process. Decision trees, for instance, are interpretable but prone to overfitting, while neural networks can capture complex relationships but require larger datasets and more computational resources. AWS SageMaker provides built-in algorithms and frameworks such as XGBoost, linear learners, and deep learning containers for TensorFlow and PyTorch, allowing engineers to experiment with multiple approaches and select the best-performing model.
Model Deployment And Operationalization
Deploying a machine learning model on AWS involves several considerations beyond simply making it available for predictions. Engineers must ensure low latency, scalability, and integration with existing applications. SageMaker endpoints enable real-time inference, while batch transform jobs allow large datasets to be processed in a scheduled or on-demand manner. Multi-model endpoints help optimize costs by hosting multiple models on a single endpoint.
Operationalizing models also requires monitoring for data drift, concept drift, and other issues that can degrade performance over time. Tools like Amazon CloudWatch and SageMaker Model Monitor allow engineers to track prediction quality and resource utilization. Setting up automated retraining pipelines ensures that models adapt to evolving data patterns without manual intervention, which is a key aspect of production-ready machine learning systems.
Security And Compliance Considerations
Machine learning engineers working on AWS must also be aware of security and compliance requirements. Protecting sensitive data, ensuring encryption at rest and in transit, and managing access through IAM roles are fundamental practices. AWS services provide mechanisms to secure model artifacts, data, and inference endpoints. Additionally, compliance frameworks like HIPAA, GDPR, and SOC 2 often dictate how data is stored, processed, and shared. Understanding these regulations and applying them in the design of machine learning solutions is critical, particularly in industries like healthcare, finance, and government.
Cost Management And Resource Optimization
Efficient use of cloud resources is another vital skill. Machine learning workloads can be resource-intensive, so engineers must design solutions that balance performance and cost. SageMaker offers features such as managed spot training, automatic model tuning, and elastic endpoints that optimize both cost and efficiency. Understanding the pricing models of various AWS services allows engineers to make informed decisions when designing ML pipelines, ensuring that organizations derive maximum value without unnecessary expenditure.
Continuous Learning And Adaptation
The field of machine learning on AWS is rapidly evolving. Engineers must stay current with new algorithms, frameworks, and AWS service updates. Continuous learning is not just about improving technical skills but also about understanding emerging best practices in operationalizing models, ethical AI considerations, and interpretability techniques. Professionals who achieve the MLA-C01 certification are expected to demonstrate the ability to apply their knowledge in dynamic and complex environments, solving real-world business problems efficiently.
Advanced Deep Learning Techniques On AWS
Deep learning has become a cornerstone of modern machine learning applications, enabling the solution of complex problems such as image recognition, natural language processing, and speech analysis. For an AWS machine learning engineer, mastering deep learning involves understanding both the theoretical foundations and the practical deployment of models in a cloud environment. AWS provides specialized services like SageMaker, Deep Learning Containers, and Elastic Inference to facilitate deep learning workflows at scale. Engineers must understand concepts such as convolutional neural networks, recurrent neural networks, transformers, and attention mechanisms, and how these architectures can be applied to real-world tasks.
Implementing deep learning models requires careful attention to data quality, computational resources, and hyperparameter tuning. Training neural networks on large datasets often demands GPU or TPU acceleration to reduce computation time. AWS allows engineers to provision optimized instances with GPU support, enabling faster experimentation and model iteration. Beyond training, inference efficiency is crucial. Engineers must ensure that models deliver predictions within acceptable latency thresholds while optimizing cost and resource utilization. Techniques like model quantization, pruning, and mixed-precision training help achieve this balance.
Natural Language Processing And Text-Based Models
Natural language processing is an area where machine learning engineers must combine linguistic understanding with algorithmic expertise. NLP tasks include sentiment analysis, entity recognition, machine translation, and text summarization. AWS offers frameworks such as Amazon Comprehend and prebuilt deep learning containers to accelerate NLP solution development. Understanding tokenization, embeddings, sequence modeling, and attention mechanisms is essential for building robust text-based models.
Engineers must also consider challenges unique to NLP, such as handling large vocabularies, managing out-of-vocabulary terms, and dealing with noisy or unstructured text. Pretrained transformer models, including BERT and GPT-based architectures, provide a starting point for many applications. Fine-tuning these models on domain-specific datasets improves performance, but it requires careful management of overfitting and computational load. Additionally, ethical considerations, bias mitigation, and interpretability are particularly important in NLP, as models can inadvertently propagate harmful or inaccurate information if not carefully designed.
Reinforcement Learning And Sequential Decision Making
Reinforcement learning is an advanced technique that enables agents to learn optimal behaviors through interactions with an environment. AWS supports reinforcement learning experiments via SageMaker RL, which provides built-in environments and algorithms to simplify experimentation. Understanding the principles of rewards, policies, value functions, and exploration versus exploitation is fundamental for engineers applying these techniques.
Real-world applications of reinforcement learning include recommendation systems, robotics, dynamic pricing, and resource optimization. Engineers must consider the trade-offs between simulation fidelity and computational cost, as training RL agents can require extensive iterations. Integrating RL models into production also involves monitoring agent behavior and ensuring that the learned strategies remain safe, efficient, and aligned with business objectives.
Automated Machine Learning And Model Optimization
Automated machine learning is increasingly important for streamlining model development and improving productivity. AWS SageMaker Autopilot allows engineers to automatically preprocess data, select algorithms, and optimize hyperparameters. While automation accelerates experimentation, engineers must maintain an understanding of the underlying processes to ensure interpretability, fairness, and robustness.
Hyperparameter tuning remains a critical skill, as it directly impacts model performance. Techniques such as grid search, random search, and Bayesian optimization are commonly applied. Understanding how to define appropriate search spaces, evaluate candidate models, and avoid overfitting is essential. Engineers must also consider multi-objective optimization, balancing accuracy, latency, and cost constraints for production-ready models.
Handling Large-Scale Data And Distributed Training
Machine learning at scale presents challenges in both data management and computational efficiency. AWS provides services for distributed data storage and processing, including S3, Redshift, and EMR, which allow engineers to handle massive datasets without compromising performance. For training large models, distributed training techniques, such as data parallelism and model parallelism, are critical. Engineers must design training pipelines that minimize communication overhead while maximizing utilization of GPU clusters.
In addition to computational efficiency, managing data pipelines is essential for reproducibility and reliability. Engineers must implement robust ETL (Extract, Transform, Load) workflows, monitor data quality, and ensure that preprocessing steps are consistent across training and inference environments. Failure to maintain consistent pipelines can lead to model drift, degraded accuracy, or unexpected behavior in production systems.
Model Interpretability And Explainability
Interpretability is a key consideration for production-ready machine learning models. Engineers must ensure that stakeholders can understand why models make certain predictions, particularly in regulated industries. Techniques such as SHAP values, LIME, and feature importance analysis provide insights into model behavior. AWS SageMaker Clarify offers tools to detect bias and assess feature impact, supporting engineers in building transparent and accountable models.
Understanding model interpretability goes beyond technical implementation; it also involves communicating findings effectively to non-technical audiences. Engineers must translate complex model behavior into actionable insights while highlighting potential limitations and uncertainties. This skill is critical for building trust in machine learning systems and ensuring that decisions made by models are aligned with organizational goals and ethical standards.
Continuous Integration And Continuous Deployment For Machine Learning
Machine learning engineering on AWS requires a DevOps-like approach to ensure that models remain reliable and up-to-date. Continuous integration and continuous deployment (CI/CD) pipelines for ML involve automating testing, validation, deployment, and monitoring processes. Engineers must design workflows that automatically retrain models when new data becomes available, validate performance improvements, and deploy updates without disrupting existing services.
Automation tools such as AWS CodePipeline, Lambda functions, and SageMaker pipelines facilitate CI/CD for machine learning. Engineers must consider versioning for datasets, preprocessing scripts, and model artifacts to maintain reproducibility. Implementing robust rollback mechanisms is also important, as updates to production models can introduce unexpected errors or degrade performance if not carefully validated.
Ethical Considerations And Responsible AI
Ethical considerations are increasingly critical for machine learning engineers. AWS professionals must design models that minimize bias, respect privacy, and operate transparently. This involves careful dataset selection, bias detection, and fairness assessment throughout the model lifecycle. Engineers should also implement mechanisms for human oversight in decision-making processes, especially in applications with high-stakes consequences.
Responsible AI practices include monitoring model outputs for unintended behaviors, maintaining audit logs, and ensuring compliance with legal and regulatory frameworks. These considerations are not merely optional; they are integral to creating sustainable, trustworthy, and socially responsible machine learning systems.
Future Trends And Emerging Techniques
Staying ahead in the field requires awareness of emerging trends such as federated learning, self-supervised learning, and hybrid architectures combining symbolic reasoning with deep learning. AWS continues to introduce services and frameworks that support experimentation with cutting-edge methods. Machine learning engineers must be prepared to evaluate the practical applicability of these techniques, integrating them where appropriate to solve novel business problems efficiently.
Federated learning, for example, allows models to be trained across decentralized data sources without transferring sensitive information, offering advantages in privacy-sensitive domains. Self-supervised learning reduces the need for labeled datasets, enabling engineers to leverage massive volumes of raw data. Understanding these trends equips engineers to build scalable, innovative solutions while maintaining high ethical and operational standards.
Collaboration And Cross-Functional Skills
Finally, success as an AWS machine learning engineer requires collaboration and communication skills. Engineers often work alongside data scientists, software developers, business analysts, and domain experts. Translating technical findings into actionable insights, designing scalable solutions that integrate with broader systems, and aligning ML strategies with organizational objectives are critical components of the role.
Collaboration extends to sharing knowledge about best practices, documenting workflows, and mentoring junior team members. Engineers who can combine deep technical expertise with effective communication are better positioned to drive innovation and ensure that machine learning initiatives deliver tangible business value.
Feature Engineering And Data Preparation
Feature engineering remains a cornerstone of effective machine learning. Understanding which features to include, transform, or exclude can dramatically impact model performance. AWS engineers must be skilled in creating new features from raw data, encoding categorical variables, normalizing numeric data, and handling missing values. Techniques such as one-hot encoding, label encoding, binning, and feature scaling are essential but often need to be adapted based on dataset characteristics.
Beyond traditional preprocessing, automated feature selection and dimensionality reduction are critical when dealing with large datasets. Methods such as principal component analysis, t-SNE, and autoencoders help reduce noise and redundancy, improving training efficiency and model interpretability. Engineers must also consider feature interactions, as combining multiple variables can reveal hidden patterns that single features cannot capture. Proper feature engineering requires not only technical skill but also a deep understanding of the domain to generate meaningful, informative features.
Advanced Model Evaluation And Metrics
Evaluating machine learning models extends beyond simple accuracy or loss measurements. AWS ML engineers must select metrics aligned with business objectives and the type of problem, whether it is classification, regression, or ranking. Metrics like precision, recall, F1 score, ROC-AUC, and log-loss are essential for classification tasks, while RMSE, MAE, and R² are critical for regression problems.
For imbalanced datasets, standard accuracy can be misleading, so metrics that account for class distribution are necessary. Engineers must also implement robust cross-validation techniques, including k-fold, stratified, or time-based splits, to ensure performance generalizes across unseen data. Additionally, understanding how to interpret confusion matrices, precision-recall curves, and cumulative gain charts helps diagnose model weaknesses and informs strategies for improvement.
Model Deployment And Production Considerations
Deploying machine learning models in production is a complex task requiring attention to scalability, reliability, and efficiency. AWS provides services such as SageMaker endpoints, Lambda, and API Gateway to facilitate model deployment. Engineers must design endpoints that handle concurrent requests, provide low-latency predictions, and integrate seamlessly with other systems.
Monitoring deployed models is equally critical. Engineers should implement logging, alerting, and performance tracking to detect degradation over time. Concepts such as model drift and concept drift—changes in data distribution or relationships over time—can significantly impact model performance. Addressing these issues may involve retraining models, updating feature pipelines, or implementing online learning systems to adapt continuously to new data.
Hyperparameter Tuning And Optimization
Hyperparameter optimization is a crucial aspect of building high-performing models. Beyond automated tuning, engineers should understand the impact of each hyperparameter on model behavior. Grid search, random search, and Bayesian optimization are widely used, but advanced techniques such as hyperband or population-based training can further enhance efficiency.
Understanding how hyperparameters interact, especially in complex models like deep neural networks or gradient boosting machines, allows engineers to prioritize adjustments that yield the largest performance gains. Balancing exploration of hyperparameter space with computational cost is key, particularly in cloud environments where resource usage directly affects cost and training time.
Scaling Machine Learning Workloads
As datasets grow in size and complexity, scaling machine learning workloads becomes essential. Engineers must design distributed training pipelines that leverage multiple GPUs or CPU clusters while minimizing communication overhead. Techniques like data parallelism, model parallelism, and pipeline parallelism enable efficient resource utilization and faster convergence.
In addition to computational scaling, data scaling strategies are important. Incremental learning, streaming data pipelines, and batch processing allow engineers to train models on continuously growing datasets without requiring retraining from scratch. AWS services such as S3, EMR, and Redshift provide infrastructure to manage massive data efficiently, enabling engineers to focus on model development rather than data bottlenecks.
Advanced Ensemble Techniques
Ensemble methods combine multiple models to improve performance, reduce overfitting, and increase robustness. Common approaches include bagging, boosting, stacking, and voting classifiers. AWS ML engineers must understand when to apply each method, the trade-offs involved, and how to tune base learners effectively.
For example, gradient boosting machines such as XGBoost or LightGBM often outperform single models on tabular data, but they require careful regularization and hyperparameter tuning. Stacking combines heterogeneous models, leveraging complementary strengths, but demands careful cross-validation to prevent information leakage. Ensemble learning requires both analytical skill and practical experimentation to achieve optimal results.
Model Explainability And Bias Detection
Interpretability remains a critical aspect of production machine learning. Engineers must ensure that models can be explained to stakeholders and regulators. Techniques such as SHAP, LIME, permutation importance, and partial dependence plots provide insights into feature contributions and decision-making logic.
Bias detection is another essential consideration. Models trained on biased datasets can propagate systemic errors or unfair treatment of specific groups. AWS SageMaker Clarify and other frameworks allow engineers to assess bias and fairness metrics, implement mitigation strategies, and maintain transparency throughout the ML lifecycle. Understanding both the technical and ethical dimensions of explainability ensures that ML solutions are trustworthy and socially responsible.
Security And Compliance Considerations
Security and compliance are critical when handling sensitive data or deploying models in regulated environments. Engineers must implement encryption at rest and in transit, control access via IAM roles, and adhere to governance standards. AWS provides built-in security tools, but engineers must design workflows that enforce best practices for data protection.
Additionally, regulatory compliance often requires auditability, reproducibility, and proper data retention policies. Engineers should maintain detailed logs of data transformations, model training runs, and deployment changes to ensure accountability. By integrating security and compliance considerations into every stage of the ML lifecycle, engineers reduce risks and enhance trust in deployed systems.
Time Series And Sequential Data
Time series data presents unique challenges and opportunities for machine learning engineers. Forecasting, anomaly detection, and pattern recognition are common tasks requiring models that capture temporal dependencies. Techniques such as ARIMA, Prophet, LSTMs, and transformers adapted for sequences are often applied.
Feature engineering for time series data includes creating lag features, rolling statistics, seasonality indicators, and trend components. Handling irregular intervals, missing timestamps, and varying granularity adds complexity. Engineers must also evaluate models using appropriate metrics such as mean absolute percentage error (MAPE) or dynamic time warping to ensure predictions align with business objectives.
Experimentation And Iterative Development
A robust experimentation process is fundamental to advancing model performance. AWS ML engineers should adopt an iterative approach, testing hypotheses, evaluating results, and refining models based on data-driven insights. Tools such as SageMaker Experiments enable tracking multiple runs, capturing hyperparameters, and comparing outcomes.
This iterative mindset fosters creativity and learning. Engineers can explore alternative architectures, feature sets, or training strategies while systematically documenting findings. A disciplined experimentation approach ensures that improvements are reproducible, meaningful, and aligned with overarching project goals.
Collaboration With Data Engineering And DevOps
Machine learning engineering does not operate in isolation. Successful deployment requires collaboration with data engineers, DevOps teams, and business stakeholders. Data pipelines must be reliable, scalable, and optimized for model consumption. CI/CD practices for ML, including versioning datasets and models, automated testing, and deployment monitoring, ensure that ML systems remain robust and maintainable.
Effective collaboration also involves communicating technical decisions and results to non-technical teams. Engineers must translate complex analyses into actionable insights, provide guidance on model limitations, and align ML strategies with organizational objectives. Strong collaboration and communication skills complement technical expertise, making engineers more effective in delivering impactful ML solutions.
Continuous Learning And Staying Current
The field of machine learning evolves rapidly. Engineers preparing for MLA-C01 certification must adopt a mindset of continuous learning, exploring new algorithms, frameworks, and AWS services. Staying current requires engaging with research literature, experimenting with emerging techniques, and evaluating their applicability in real-world projects.
Continuous learning also involves reflecting on past experiments, understanding failures, and documenting lessons learned. Engineers who cultivate curiosity, adaptability, and analytical rigor are better equipped to tackle complex challenges and deliver innovative, reliable machine learning solutions on AWS.
Advanced Deep Learning Architectures
Deep learning architectures are at the core of solving complex problems in image, text, and speech domains. Engineers preparing for MLA-C01 certification need to understand the differences and applications of convolutional neural networks, recurrent neural networks, transformers, and attention mechanisms. CNNs excel at spatial feature extraction in images, while RNNs and LSTMs capture temporal dependencies in sequences. Transformers, particularly with attention mechanisms, have revolutionized natural language processing by allowing models to focus on relevant parts of input sequences efficiently. Understanding these architectures involves not only grasping their structure but also knowing when and how to apply them to real-world problems.
Training deep neural networks requires careful consideration of initialization, activation functions, and normalization layers. Improper initialization can slow convergence or trap models in local minima. Activation functions such as ReLU, Leaky ReLU, or GELU influence gradient flow and model nonlinearity. Batch normalization and layer normalization improve stability and accelerate training by reducing internal covariate shift. Engineers must also be aware of overfitting in deep networks and implement strategies such as dropout, data augmentation, and early stopping to maintain generalization.
Transfer Learning And Pretrained Models
Transfer learning is a practical approach for leveraging existing knowledge embedded in pretrained models. By fine-tuning models on domain-specific data, engineers can achieve high performance without training from scratch. AWS offers pretrained models for image classification, object detection, and NLP tasks, which can be adapted to custom problems.
Fine-tuning requires careful selection of which layers to freeze and which to train. Lower layers often capture general patterns, while higher layers capture domain-specific features. Engineers must experiment with learning rates, regularization, and batch sizes to optimize performance while avoiding catastrophic forgetting, where the model loses valuable general knowledge. Transfer learning not only reduces computational cost but also enables engineers to tackle small or specialized datasets effectively.
Generative Models And Synthetic Data
Generative models, such as variational autoencoders and generative adversarial networks, are powerful tools for creating synthetic data. Synthetic data can augment real datasets, improve model robustness, and address privacy concerns. Understanding the principles behind generative modeling, including latent space representation, adversarial training, and reconstruction loss, is essential for engineers working with complex datasets.
Training generative models requires balancing generator and discriminator dynamics in GANs, monitoring convergence, and avoiding mode collapse. Synthetic data must be evaluated carefully to ensure it maintains the statistical properties of real data. Engineers must also consider ethical implications, particularly in generating data that could misrepresent or bias real-world outcomes. Generative modeling combines creativity with rigorous evaluation to enhance machine learning capabilities.
Reinforcement Learning Fundamentals
Reinforcement learning provides frameworks for decision-making in dynamic environments. AWS ML engineers need to understand concepts such as states, actions, rewards, policies, and value functions. Techniques like Q-learning, policy gradients, and actor-critic methods enable models to learn optimal strategies through trial and error.
Implementing reinforcement learning requires attention to exploration-exploitation trade-offs, reward shaping, and stability of learning algorithms. Engineers must also consider computational cost, as many RL algorithms require significant simulation or interaction with environments. Understanding RL is particularly valuable for applications in robotics, recommendation systems, and adaptive control, where decisions evolve over time and depend on feedback from the environment.
Advanced Natural Language Processing
NLP continues to be a fast-evolving area in machine learning. AWS engineers must be familiar with tokenization strategies, embedding methods, sequence-to-sequence models, and transformer-based architectures such as BERT or GPT. Fine-tuning pretrained language models allows adaptation to specialized tasks like sentiment analysis, question answering, or text summarization.
Preprocessing text data involves normalization, handling out-of-vocabulary words, and leveraging subword tokenization for efficient representation. Engineers should understand attention mechanisms, positional encoding, and multi-head attention to interpret how transformers capture context. Evaluating NLP models requires metrics such as BLEU, ROUGE, or perplexity, depending on whether the task is generation, classification, or translation. Advanced NLP knowledge enables engineers to create solutions that understand and generate human language effectively.
Hyperparameter Sensitivity And Model Robustness
Robustness in machine learning models often depends on sensitivity to hyperparameters and environmental variations. AWS ML engineers must develop a systematic approach to identify sensitive hyperparameters and assess model stability. Techniques such as sensitivity analysis, ablation studies, and randomized experimentation help identify which parameters significantly impact performance.
In addition to hyperparameter tuning, engineers must consider robustness to noise, adversarial attacks, and distribution shifts. Defensive strategies include adversarial training, data augmentation, regularization techniques, and model ensembling. Understanding these aspects ensures that deployed models maintain performance in diverse real-world scenarios rather than only under controlled experimental conditions.
Automated Machine Learning And Pipelines
Automated machine learning (AutoML) is increasingly relevant for reducing manual experimentation. Engineers must understand how to define pipelines that automate preprocessing, feature selection, model selection, and hyperparameter tuning. While AutoML tools can accelerate development, engineers still need deep understanding to interpret results, avoid overfitting, and validate model assumptions.
Building robust pipelines involves handling data drift, retraining schedules, and model versioning. AWS provides services to orchestrate pipelines and monitor performance over time. Engineers should ensure that automation complements human insight rather than replacing critical decision-making processes. Effective pipelines integrate automation with reproducible and explainable workflows.
Edge Machine Learning And Deployment Constraints
Deploying machine learning models at the edge introduces constraints such as limited compute, memory, and power. Engineers must adapt model architectures for efficiency, applying techniques like quantization, pruning, and knowledge distillation to reduce resource requirements.
Edge deployment also necessitates considerations for latency, reliability, and offline operation. Engineers must ensure that models can perform consistently without constant connectivity and can handle updates or retraining efficiently. These challenges demand a combination of algorithmic innovation and practical engineering to maintain performance in constrained environments.
Observability And Model Lifecycle Management
Observability extends beyond monitoring deployed models. Engineers must track data inputs, model predictions, drift detection, and system performance comprehensively. Implementing observability allows for early detection of anomalies, degraded predictions, or potential failures in production.
Lifecycle management encompasses training, validation, deployment, monitoring, retraining, and eventual decommissioning of models. Engineers must ensure traceability and reproducibility, documenting versions of datasets, preprocessing steps, and model configurations. Lifecycle management practices enhance reliability, reduce risk, and support regulatory compliance in production machine learning systems.
Ethical Considerations And Responsible AI
Responsible AI practices are integral to professional machine learning engineering. Engineers must be aware of the societal impact of their models, addressing issues such as fairness, bias, privacy, and transparency. Techniques for bias detection, mitigation, and transparency should be applied throughout the model lifecycle, from dataset creation to deployment.
Understanding the ethical dimension requires engineers to consider not only the immediate technical performance but also long-term consequences for users and stakeholders. Incorporating responsible AI principles strengthens trust, ensures regulatory adherence, and promotes sustainable adoption of machine learning solutions.
Continuous Experimentation And Knowledge Sharing
AWS ML engineers must cultivate a culture of continuous experimentation and knowledge sharing. Regularly reviewing past experiments, documenting findings, and disseminating insights improves both individual and team performance. Experimentation frameworks allow systematic comparison of models, hyperparameters, and architectures, fostering evidence-based decision-making.
Knowledge sharing also supports scalability within teams, ensuring that lessons learned are accessible and reusable. Engineers who balance rigorous experimentation with collaborative learning drive innovation and maintain high standards of quality across machine learning initiatives.
Future Trends And Emerging Technologies
Remaining aware of emerging technologies and research trends is crucial for long-term success in machine learning. Areas such as self-supervised learning, federated learning, neuromorphic computing, and energy-efficient AI are reshaping the landscape. AWS ML engineers must be prepared to evaluate these approaches, experiment with them, and integrate relevant innovations into practical workflows.
Anticipating trends also involves critical thinking about potential challenges, including ethical implications, resource demands, and system integration. Engineers who combine technical expertise with foresight and adaptability are well-positioned to create resilient, cutting-edge solutions in a rapidly evolving field.
Final Words
The AWS Certified Machine Learning Engineer – Associate MLA-C01 exam blog serves as a comprehensive and rare resource for anyone aiming to excel in this certification. Throughout the preparation process, the integration of advanced topics such as deep learning architectures, reinforcement learning, generative models, and transformer-based NLP models allows learners to gain both conceptual and practical expertise. Unlike many standard guides, the blog emphasizes real-world applications of machine learning, including edge deployments, model lifecycle management, AutoML pipelines, and ethical AI considerations. This ensures that candidates not only prepare for the exam but also acquire skills that are highly relevant in professional environments.
Practice tests and dumps mentioned in the blog act as a crucial reinforcement mechanism. By repeatedly testing knowledge and understanding, candidates can identify weak areas, measure progress, and solidify concepts that are often abstract or challenging. The careful integration of CertBolt within the content offers a structured approach to prioritizing high-value topics, saving preparation time while ensuring coverage of essential subjects. This guidance is particularly valuable for learners who want a balance between depth of understanding and efficient exam readiness.
Another strength of the blog is its attention to emerging and advanced topics in machine learning. Self-supervised learning, federated learning, hyperparameter sensitivity, and observability are often underrepresented in standard resources but are addressed thoughtfully here. By including these areas, the blog prepares candidates for a broader scope of the exam and equips them with insights applicable to complex real-world ML problems. Additionally, the blog’s practical tips for scenario-based questions, combined with structured learning through practice tests and dumps, foster confidence and reduce exam anxiety.
In conclusion, this blog is more than an exam guide; it is a strategic preparation tool and an educational resource that bridges theoretical knowledge and practical application. Its focus on advanced topics, ethical considerations, structured practice, and real-world scenarios makes it an indispensable companion for anyone pursuing the AWS Certified Machine Learning Engineer – Associate MLA-C01 certification, ensuring candidates are well-prepared to succeed in both the exam and their professional ML careers.
Pass your Amazon AWS Certified Machine Learning Engineer - Associate MLA-C01 certification exam with the latest Amazon AWS Certified Machine Learning Engineer - Associate MLA-C01 practice test questions and answers. Total exam prep solutions provide shortcut for passing the exam by using AWS Certified Machine Learning Engineer - Associate MLA-C01 Amazon certification practice test questions and answers, exam dumps, video training course and study guide.
-
Amazon AWS Certified Machine Learning Engineer - Associate MLA-C01 practice test questions and Answers, Amazon AWS Certified Machine Learning Engineer - Associate MLA-C01 Exam Dumps
Got questions about Amazon AWS Certified Machine Learning Engineer - Associate MLA-C01 exam dumps, Amazon AWS Certified Machine Learning Engineer - Associate MLA-C01 practice test questions?
Click Here to Read FAQ -
-
Top Amazon Exams
- AWS Certified Generative AI Developer - Professional AIP-C01 - AWS Certified Generative AI Developer - Professional AIP-C01
- AWS Certified Solutions Architect - Associate SAA-C03 - AWS Certified Solutions Architect - Associate SAA-C03
- AWS Certified Solutions Architect - Professional SAP-C02 - AWS Certified Solutions Architect - Professional SAP-C02
- AWS Certified AI Practitioner AIF-C01 - AWS Certified AI Practitioner AIF-C01
- AWS Certified Cloud Practitioner CLF-C02 - AWS Certified Cloud Practitioner CLF-C02
- AWS Certified Security - Specialty SCS-C03 - AWS Certified Security - Specialty SCS-C03
- AWS Certified Machine Learning Engineer - Associate MLA-C01 - AWS Certified Machine Learning Engineer - Associate MLA-C01
- AWS Certified CloudOps Engineer - Associate SOA-C03 - AWS Certified CloudOps Engineer - Associate SOA-C03
- AWS Certified DevOps Engineer - Professional DOP-C02 - AWS Certified DevOps Engineer - Professional DOP-C02
- AWS Certified Advanced Networking - Specialty ANS-C01 - AWS Certified Advanced Networking - Specialty ANS-C01
- AWS Certified Data Engineer - Associate DEA-C01 - AWS Certified Data Engineer - Associate DEA-C01
- AWS Certified Developer - Associate DVA-C02 - AWS Certified Developer - Associate DVA-C02
- AWS Certified Security - Specialty SCS-C02 - AWS Certified Security - Specialty SCS-C02
- AWS Certified SysOps Administrator - Associate - AWS Certified SysOps Administrator - Associate (SOA-C02)
-
Purchase Amazon AWS Certified Machine Learning Engineer - Associate MLA-C01 Exam Training Products Individually
Last Week Results!
Get PDF Version of AWS Certified Machine Learning Engineer - Associate MLA-C01 Questions & Answers
With the PDF Version of the exam questions, you can study at any time and place, which are convenient to you. This means that you can work with the AWS Certified Machine Learning Engineer - Associate MLA-C01 Questions & Answers PDF Version on your PC or use it on your portable device while on the way to your work or home. The PDF exam file also offers you the possibility to print it and use this printed version if you prefer it over the digital one.
Since the file is in the .pdf format, you can open it with a wide range of programs and applications, including Google Docs, OpenOffice, and Adobe Acrobat Reader DC. It is a convenient and easy-to-use option that will help you master new knowledge and skills with relevant materials.
* PDF Version is an add-on to your purchase of AWS Certified Machine Learning Engineer - Associate MLA-C01 Questions & Answers and can't be purchased separately.
Only Registered Members can Download Exam Demo Questions & Answers
Please fill out your email address below in order to exam demo Questions & Answers.
Registration is Free and Easy, You Simply need to provide a valid email address.
- Trusted by hundreds of IT Certification Candidates Every Month
- 1200+ Exams Available
- Instant download After Registration