Amazon AWS Certified Data Engineer - Associate DEA-C01 Bundle
- Exam: AWS Certified Data Engineer - Associate DEA-C01
- Exam Provider: Amazon

Latest Amazon AWS Certified Data Engineer - Associate DEA-C01 Exam Dumps Questions
Amazon AWS Certified Data Engineer - Associate DEA-C01 Exam Dumps, practice test questions, Verified Answers, Fast Updates!
-
-

AWS Certified Data Engineer - Associate DEA-C01 Questions & Answers
366 Questions & Answers
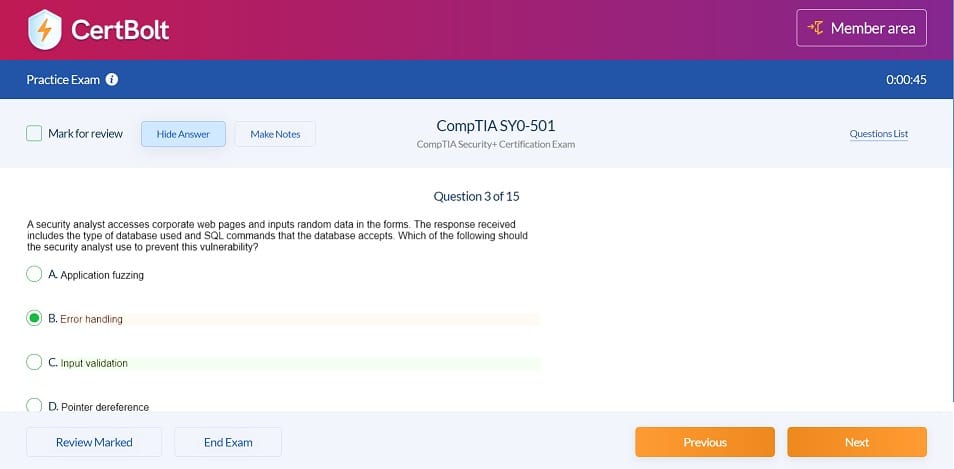
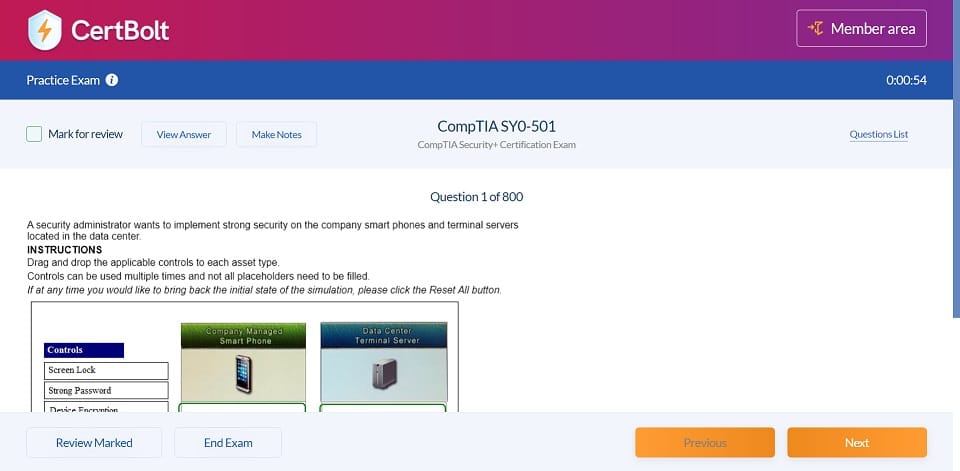
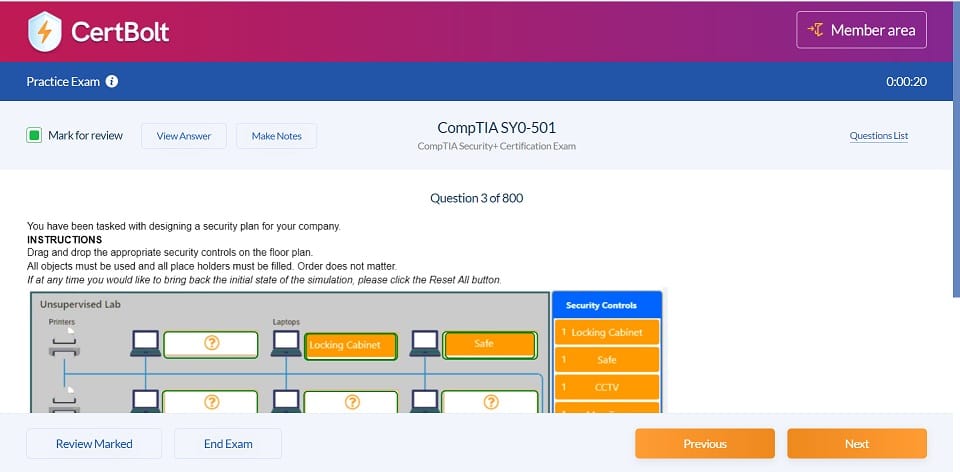
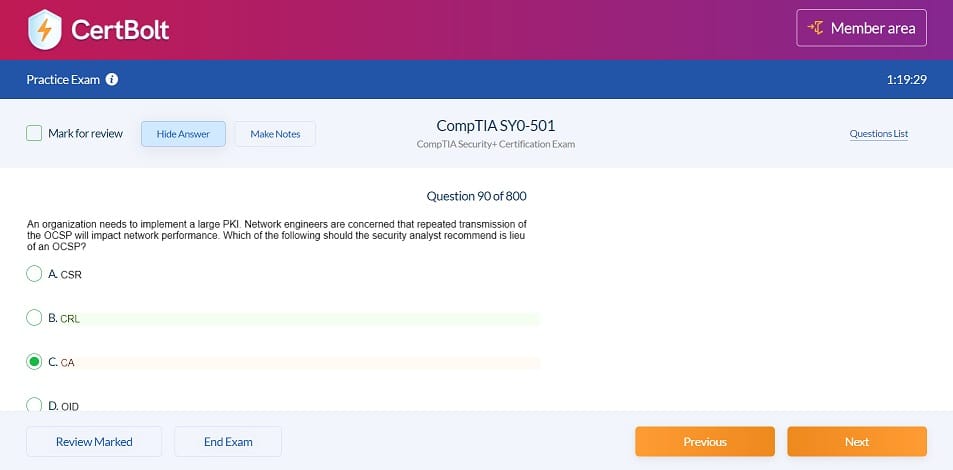
Includes 100% Updated AWS Certified Data Engineer - Associate DEA-C01 exam questions types found on exam such as drag and drop, simulation, type in, and fill in the blank. Fast updates, accurate answers for Amazon AWS Certified Data Engineer - Associate DEA-C01 exam. Exam Simulator Included!
-

AWS Certified Data Engineer - Associate DEA-C01 Online Training Course
273 Video Lectures
Learn from Top Industry Professionals who provide detailed video lectures based on 100% Latest Scenarios which you will encounter in exam.
-

AWS Certified Data Engineer - Associate DEA-C01 Study Guide
809 PDF Pages
Study Guide developed by industry experts who have written exams in the past. Covers in-depth knowledge which includes Entire Exam Blueprint.
-
-
Amazon AWS Certified Data Engineer - Associate DEA-C01 Exam Dumps, Amazon AWS Certified Data Engineer - Associate DEA-C01 practice test questions
100% accurate & updated Amazon certification AWS Certified Data Engineer - Associate DEA-C01 practice test questions & exam dumps for preparing. Study your way to pass with accurate Amazon AWS Certified Data Engineer - Associate DEA-C01 Exam Dumps questions & answers. Verified by Amazon experts with 20+ years of experience to create these accurate Amazon AWS Certified Data Engineer - Associate DEA-C01 dumps & practice test exam questions. All the resources available for Certbolt AWS Certified Data Engineer - Associate DEA-C01 Amazon certification practice test questions and answers, exam dumps, study guide, video training course provides a complete package for your exam prep needs.
AWS Certified Data Engineer – Associate Certification
The AWS Certified Data Engineer – Associate certification focuses on validating skills required to build, deploy, and maintain data pipelines and systems on the AWS platform. This certification is tailored for professionals involved in transforming, storing, securing, and analyzing data in distributed systems. It emphasizes the hands-on ability to implement best practices across data lifecycle processes, rather than theoretical knowledge or isolated platform expertise.
This exam bridges a crucial gap in AWS certifications. Previously, professionals working on data lakes, data warehouses, and real-time data workflows had to rely on more generic certifications. The DEA-C01 exam recognizes the growing need for specialization in the domain of data engineering, particularly in a cloud-native environment.
The Shift from Traditional to Modern Data Engineering
The role of the data engineer has evolved. Where data engineers were once focused on managing relational databases or maintaining ETL jobs in scheduled batch processes, they are now responsible for orchestrating large-scale data workflows across complex cloud environments. With the shift toward serverless computing, streaming analytics, data lakes, and AI-driven applications, data engineers are now expected to architect robust pipelines that are highly available, cost-efficient, and scalable.
The DEA-C01 exam reflects this shift. It evaluates not only an individual’s knowledge of services like AWS Glue, Amazon Redshift, or Amazon Kinesis but also their ability to make design decisions based on evolving business requirements. Candidates are expected to understand integration strategies, performance tuning, and failure handling in dynamic, large-scale pipelines.
Core Competencies Measured in the DEA-C01 Exam
While the exam blueprint is detailed, the core competencies fall into specific categories:
Data Ingestion and Transformation
Candidates must be able to implement and manage ingestion pipelines from diverse sources such as APIs, on-premises databases, or IoT devices. This includes understanding which ingestion method is optimal—real-time streaming using Kinesis, or batch loading using Glue or Data Pipeline. An in-depth understanding of Glue jobs, transformations using PySpark, and orchestrating workflows using triggers and crawlers is essential.
Data Storage and Management
The certification expects candidates to demonstrate proficiency in managing structured, semi-structured, and unstructured data using services like Amazon S3, Amazon Redshift, AWS Lake Formation, and DynamoDB. Storage optimization, partitioning strategies, and data lifecycle management are critical knowledge areas. Understanding the trade-offs between columnar and row-based storage formats like Parquet, ORC, JSON, or CSV plays a major role in decision-making.
Data Security
Data security is foundational in every pipeline and architecture built on AWS. Candidates must demonstrate their ability to implement encryption at rest and in transit, manage access control using IAM policies, and secure data using KMS keys. This includes the application of least privilege principles, data classification, masking techniques, and audit mechanisms.
Data Analysis and Visualization
While the exam does not expect candidates to build dashboards, it requires a strong understanding of preparing data for downstream analytics. This includes optimizing Redshift queries, managing Glue Data Catalog metadata, and ensuring interoperability between services like Athena, QuickSight, and Redshift Spectrum. Designing systems that support high-performance analytical workloads is key.
Operational Excellence and Monitoring
Monitoring and observability are essential in production-grade pipelines. Candidates should know how to implement logging and metrics using CloudWatch, trace job executions in Glue, handle failure retries, and manage alerts. Understanding error-handling best practices in stream processing systems like Kinesis or Firehose is also necessary.
What Makes This Certification Different
Unlike other associate-level AWS certifications, this exam is not just about configuring services correctly. It evaluates holistic problem-solving—choosing between services based on cost, latency, throughput, and availability. The questions often present scenario-based challenges that force the test-taker to select the best solution from multiple technically valid options.
Another unique feature is the strong presence of open-source and third-party tool knowledge. Although the focus remains on AWS-native services, familiarity with tools such as Apache Spark, Airflow, or Kafka can give candidates an edge. The architecture of data workflows often mirrors real-world setups, where AWS services are used in conjunction with open-source technologies.
Target Audience for the DEA-C01 Certification
This certification is ideal for data engineers, data architects, and even backend developers who have worked with AWS services related to data. It benefits those involved in building pipelines, transforming data, or maintaining data platforms. Professionals already certified in AWS Cloud Practitioner, Solutions Architect Associate, or Developer Associate will find the DEA-C01 a logical step if they wish to specialize in data engineering.
It is not intended for those looking to specialize in machine learning or business intelligence, although a foundational understanding of these areas can be helpful. The DEA-C01 is about pipeline robustness, scalability, and maintainability, rather than end-user reporting or predictive modeling.
Skills You Should Master Before Taking the Exam
To be well-prepared, candidates should be comfortable with writing and debugging ETL code, preferably in PySpark or Python. Familiarity with SQL is essential, particularly for querying Redshift or Athena. Understanding the structure and management of data lakes, metadata management, and service integration are all central to the exam.
Hands-on experience with AWS services is crucial. Setting up Glue jobs, partitioning data in S3 buckets, configuring Redshift clusters, managing schema evolution, and creating Lake Formation permissions are practical skills that need to be second nature. Without this hands-on practice, understanding scenario-based questions becomes much more difficult.
The Role of Experience in Preparation
Unlike certifications where theoretical study alone can be sufficient, DEA-C01 benefits greatly from practical experience. Having built at least a few pipelines in real-world environments using services like Glue, Redshift, and S3 will provide a level of intuition that helps during the exam. Familiarity with failure modes, bottlenecks, and data latency issues can guide the decision-making process in answering scenario-based questions.
Candidates with prior experience in building data platforms—especially those who’ve handled challenges around schema mismatches, ingestion throughput limits, or job failures—will find themselves better equipped. This real-world grounding allows them to evaluate trade-offs more realistically, as required in the exam.
Common Challenges and Misconceptions
Many candidates underestimate the depth of the exam by assuming it is similar to the Solutions Architect Associate or Developer Associate certifications. However, DEA-C01 demands specialized knowledge, particularly around large-scale data operations. Mistaking Glue Studio’s UI for its complete capability or assuming S3 is always the right storage option for all use cases can be misleading.
Another common challenge is misinterpreting cost versus performance trade-offs. Candidates should not always assume serverless services are cheaper. Services like Redshift, when configured with proper workload management, may outperform Athena in complex analytical workloads with lower long-term costs.
Time management is another hurdle. Scenario-based questions can be long, requiring careful reading to identify what the question is truly asking. Practicing these ahead of time builds the mental endurance required for the actual test.
Preparing with a Focused Strategy
While exhaustive preparation is not always feasible, a strategic approach can yield better results. Begin by reviewing real use cases of data pipelines in cloud environments. Rebuild existing pipelines in your practice environment using different AWS services and analyze the trade-offs. Create test cases where your pipeline ingests, transforms, and stores data while adhering to compliance constraints.
Use Glue to process data from S3 to Redshift, implement a crawler to update the schema, and observe how partitioning affects query performance. These practical explorations are more valuable than static reading. Similarly, configure CloudWatch alarms on a Glue job, simulate job failures, and learn to automate retries. These exercises mimic the depth of analysis needed in exam scenarios.
Understanding how IAM policies govern access to data resources and mastering the syntax and impact of those policies ensures you are not caught off guard during the test. Practice writing fine-grained access policies, KMS configurations, and resource-based permissions that can be applied to S3, Redshift, or Glue.
Understanding the Core AWS Services for Data Engineering
One of the foundational requirements for passing the AWS Certified Data Engineer – Associate exam is a practical understanding of core services within the AWS ecosystem. These services are deeply embedded in modern data workflows and are tested throughout the certification.
A data engineer must be proficient with storage services such as Amazon S3, which is commonly used for raw, curated, and transformed data layers. Amazon S3 supports data lakes at scale and enables partitioned data storage that accelerates downstream processing. Understanding how to configure S3 buckets, apply lifecycle rules, and use S3 Select for optimized reads is essential.
Ingestion and streaming services are another focal point. Amazon Kinesis and AWS Glue streaming ETL play major roles in real-time data pipelines. These tools are essential when building solutions that react to events with low latency. Kinesis Data Streams handles ingestion, while Kinesis Data Firehose allows for transformation and automatic delivery to S3 or Amazon Redshift.
Additionally, Amazon Redshift serves as a high-performance data warehouse where structured data is stored for complex analytics. Understanding its architecture, compression techniques, sort keys, and distribution styles helps data engineers design scalable and cost-effective systems.
The DEA-C01 exam also expects familiarity with AWS Glue, a serverless data integration service. From cataloging data in the Glue Data Catalog to authoring ETL jobs using Python or Scala, this service is critical for batch processing. Proper use of crawlers, job bookmarks, and development endpoints will often reflect real scenarios that a candidate must know how to handle.
Applying Hands-On Experience to Real-World Problems
What distinguishes the AWS Data Engineer certification from other theoretical certifications is its strong focus on real-world use cases. Success in this exam is tied to the ability to apply services in a context that resembles production-level data engineering.
Candidates should be able to design ingestion workflows for diverse sources, including streaming, batch, and hybrid models. For example, designing a system that ingests transactional logs from on-premise databases through AWS Database Migration Service into Amazon S3, and then feeding this into Amazon Athena or Redshift, is a pattern often tested.
Performance optimization is also emphasized. Knowing how to reduce data transfer costs, minimize processing time, and design efficient partition strategies requires more than just reading documentation. It requires hands-on practice with AWS Glue job parameters, Spark execution tuning, Redshift workload management queues, and Athena query optimization.
Another key area of practical expertise is troubleshooting. When pipelines break, logs and monitoring tools must be leveraged effectively. CloudWatch Logs, AWS Glue job logs, and Redshift system tables are all sources of operational data that assist in diagnosing and resolving failures. Demonstrating awareness of such tools within the exam reveals practical readiness for production responsibilities.
Architecting Data Solutions for Scalability and Reliability
Architectural thinking is core to being a successful data engineer on AWS. This includes choosing the right services based on data volume, velocity, and structure. The DEA-C01 exam evaluates your ability to assess trade-offs and select the most suitable patterns.
A candidate may be presented with a scenario where multiple terabytes of CSV files arrive daily and must be prepared for downstream reporting in Redshift. The optimal architecture might involve S3 as a staging area, AWS Glue for transformation, and Redshift as the target. However, nuances like whether to use Glue or EMR, when to introduce a data lake layer, and how to manage schema evolution will differentiate a good design from a poor one.
Reliability also plays a central role in solution architecture. Data engineers must understand how to build fault-tolerant systems using retry mechanisms, dead-letter queues in streaming systems, and idempotent data writes. Using Amazon SQS and Lambda for error handling or configuring Redshift Spectrum to query S3 backups in case of ETL failure demonstrates a depth of architectural knowledge.
Cost optimization is another factor in architectural decisions. For instance, using columnar formats like Parquet and ORC in S3 enables Athena and Redshift Spectrum to query only the needed columns and partitions, significantly lowering query costs. Additionally, using Glue job triggers instead of scheduled cron jobs reduces idle compute costs and promotes efficient resource utilization.
Data Transformation Techniques and Format Strategy
At the heart of most data engineering work is the need to transform raw data into usable, analytics-ready structures. This transformation occurs in different layers and is a major topic in the AWS Data Engineer certification.
AWS Glue and AWS DataBrew provide visual and code-based mechanisms to perform data cleansing, deduplication, normalization, and enrichment. Knowing when to use Glue versus DataBrew depends on the complexity and scale of transformation. Glue supports script-based transformation ideal for large datasets, while DataBrew is more suited for small-scale, visual preparation tasks.
Transformations should follow a clear data modeling strategy. The medallion architecture (bronze, silver, gold layers) is implicitly tested in the exam, even if not explicitly named. Understanding how to stage raw data in a bronze layer, transform and cleanse in the silver layer, and aggregate in the gold layer prepares you to answer scenario-based questions that mimic real-world data warehousing practices.
The selection of data formats also impacts transformation efficiency. The exam expects you to know when to use JSON, CSV, Parquet, or Avro. For example, converting raw JSON logs to columnar Parquet format significantly reduces storage and increases query performance. Similarly, awareness of schema evolution practices using AWS Glue Catalog and Lake Formation ensures compatibility and future-proofing of data lakes.
Partitioning is another critical concept in transformation. Organizing data by date, region, or user ID can enhance query performance and lower processing costs. However, over-partitioning or incorrect partition key selection can lead to performance degradation. Balancing partition size, number of files, and access patterns is a skill tested repeatedly in various forms.
Building Reliable and Scalable Data Pipelines
Orchestrating end-to-end data pipelines is where all services come together into a cohesive flow. This orchestration requires automation, fault tolerance, and event-driven execution.
Workflow orchestration in AWS can be implemented using services like AWS Step Functions, AWS Glue Workflows, and even managed Airflow on Amazon MWAA. Each has its ideal use case. Glue Workflows are tightly integrated with data jobs, whereas Step Functions are versatile for microservices coordination. Being able to differentiate and apply these services to the right scenarios is key for passing scenario-based questions.
For example, a common use case might involve a daily batch pipeline triggered by an S3 event. This pipeline crawls new data, updates the Glue catalog, runs a transformation job, and loads it into Redshift. Ensuring that each step passes execution context, handles failures gracefully, and logs output for auditability is essential in real-world systems and is equally important in the exam.
Monitoring and alerting pipelines are also part of pipeline reliability. Using CloudWatch Alarms to detect job failures, integrating with SNS to send alerts, and setting up dashboards are critical operational practices. Knowing how to track pipeline execution, set timeouts, and respond to failures reflects production-level competency.
Another important aspect of pipelines is managing dependencies and retries. Sometimes one job fails because upstream data hasn't arrived or because of transient errors. Implementing backoff strategies and conditional branching ensures resilience. Step Functions support retry logic with exponential backoff, which is a pattern often seen in exam scenarios.
Security and access control must also be embedded in pipelines. Configuring IAM roles for each service, granting least-privilege access to S3 buckets, and enabling encryption at rest and in transit are all best practices a data engineer must follow. Even when orchestrating across multiple accounts, using AWS Resource Access Manager and cross-account roles is expected knowledge.
Understanding the Technical Landscape of AWS Data Engineering
AWS Data Engineering involves a robust and evolving landscape of cloud-native tools and best practices. Candidates preparing for the DEA-C01 certification must grasp how these services interact, how data flows through them, and how they align with real-time analytics and batch processing pipelines. One of the most valuable skills tested in the DEA-C01 exam is the ability to architect scalable, secure, and cost-effective data pipelines within AWS. This requires a working knowledge of services such as data lakes, distributed storage, managed compute, and orchestration.
Unlike theoretical assessments, this certification emphasizes situational awareness. You must be able to interpret what happens when services interact at scale and how that impacts security, availability, and cost. For example, understanding the distinction between real-time stream ingestion using managed services and scheduled batch processing using orchestration tools is essential. Equally important is understanding how to optimize these data flows to reduce redundancy and cost.
Building and Managing Data Lakes
One of the core expectations of a certified AWS Data Engineer is the ability to design and maintain data lakes. These centralized repositories allow you to store structured and unstructured data at scale. A strong candidate should know how to ingest, catalog, partition, and query data efficiently. Object storage often plays a foundational role in this design. Building an effective lake architecture also includes the use of automated metadata indexing and access control.
Data lake design extends beyond raw storage. Engineers must understand how data arrives—either through direct ingestion, scheduled ETL, or event-based processing—and how it’s cataloged and secured for different user groups. The certification measures your ability to apply fine-grained access control through integrated identity policies and tagging. Maintaining data lineage and version control within the lake also supports compliance and auditability.
You also need to know how to enable query engines to interact with data lakes without requiring data movement. This serverless access to files allows for performance tuning through compression, partitioning, and format selection. Understanding when to use formats like Parquet or ORC over plain text or JSON is part of performance optimization at scale.
Working with Data Warehouses
Data engineering on AWS often includes movement between lakes and warehouses. These systems complement each other. While data lakes provide low-cost, unstructured storage, data warehouses offer optimized performance for analytics and reporting. The certification covers the decision-making process of when to materialize datasets into a warehouse and how to automate data loading from upstream pipelines.
You must understand how to create and maintain data models optimized for performance and cost. This includes practices like distribution key selection, sort key design, and workload-based optimization. The focus is not just on analytics performance but also on how to load and transform data at scale. You’ll need to automate job orchestration to ensure consistent ingestion into the warehouse from various sources.
Loading large datasets incrementally, managing schema evolution, and handling late-arriving data without duplication are also key skills. Partitioning data appropriately and using workload management to allocate computing resources are part of efficient pipeline execution. The exam evaluates your ability to keep these systems operational and predictable under changing data volumes.
Stream Processing and Real-Time Data
The DEA-C01 exam emphasizes real-time analytics as a core competency. Stream processing is no longer an optional feature in modern architectures. Candidates must demonstrate how to set up resilient, low-latency data pipelines that can process continuous streams of data without manual intervention. This involves event collection, stateful processing, and integration with analytical stores or dashboards.
Working knowledge of event-time semantics, windowing strategies, and checkpointing is required. You’ll be tested on how to configure autoscaling stream processors to handle bursts of incoming data, how to avoid duplication, and how to manage backpressure in data flow. Ensuring delivery guarantees such as exactly-once or at-least-once semantics will be central to many questions.
Candidates should be able to determine how real-time streams integrate with traditional data stores and how to orchestrate actions based on event patterns. It is common to route parsed events to multiple sinks based on event type, enrich the data on the fly, and store it in structured formats for historical analysis. These real-time use cases require the coordination of ingestion, transformation, and delivery at a granular level.
Data Orchestration and Workflow Management
Data engineers certified at the associate level are expected to design workflows that automate data movement and transformation. These workflows must be fault-tolerant, scalable, and adaptable to business requirements. Orchestration services play a key role in defining dependencies, retry policies, and failure handling. You must understand how to structure these workflows to run sequentially or in parallel, depending on the scenario.
This domain involves defining parameterized pipelines, scheduling them based on triggers or time intervals, and embedding logic for branching paths. In many cases, conditional execution is required to avoid unnecessary processing. Data engineers must design idempotent pipelines that can handle retries safely and include notification mechanisms to alert on failure.
Versioning pipeline definitions and parameterizing them for different environments is part of operational excellence. The certification assesses your understanding of infrastructure as code principles applied to data engineering, where pipeline configurations are tracked and auditable. Candidates should also be able to integrate orchestration with monitoring systems to detect and respond to anomalies in execution.
Security and Governance Considerations
The DEA-C01 certification expects you to apply security best practices throughout the data lifecycle. This includes protecting data at rest and in transit, managing encryption keys, and implementing access controls. You’ll be tested on how to ensure only authorized users and systems can interact with sensitive data and how to audit and monitor access consistently.
Candidates need to be familiar with identity-based policies and resource-based policies and know how to apply them to storage, stream, and processing services. Tagging strategies to support fine-grained access control and chargeback reporting are also included in this domain. The certification also expects awareness of how regulatory requirements such as data residency or retention may influence design.
Encryption strategies include key rotation, customer-managed keys, and integration with hardware security modules. Understanding which services automatically encrypt data and which require manual configuration is important. The exam may test your ability to implement access logging and integrate with alerting systems to detect unusual behavior or data exfiltration attempts.
Data Quality, Lineage, and Observability
Building pipelines is not enough unless they are transparent, observable, and correct. The DEA-C01 exam focuses on data quality at multiple levels. Candidates must understand how to build systems that can detect corrupt or missing data early in the pipeline. Validation techniques include schema enforcement, null-checking, deduplication, and anomaly detection.
Data lineage, or the ability to trace the origin and transformation history of a dataset, is essential for debugging and compliance. This requires proper tagging, metadata management, and integration with cataloging tools. You need to know how to implement lineage tracking without adding performance bottlenecks. This ensures users can trust the accuracy and timeliness of downstream analytics.
Observability covers logging, metrics, and alerting across your pipeline components. You’ll need to monitor ingestion throughput, transformation errors, and latency across systems. Setting up custom dashboards to visualize pipeline health and setting alerts for critical failures are considered best practices. The certification tests your ability to identify root causes quickly and restore failed processes with minimal disruption.
Cost Optimization and Operational Efficiency
Cost control is a major aspect of AWS data engineering. The certification includes your ability to design efficient pipelines that avoid unnecessary resource consumption. This involves selecting the right storage class, optimizing compute allocation, and batching data to reduce transaction frequency. You need to estimate costs and build automation that dynamically adjusts resources based on workload.
Data engineers should understand lifecycle policies for data movement across storage tiers and how to minimize storage overhead through compression and efficient file formats. Optimizing data scans in query engines and avoiding full-table reads where possible contributes significantly to performance and cost reduction.
Compute optimization includes autoscaling processing clusters, avoiding idle runtime, and scheduling jobs during off-peak hours. The certification expects you to recognize inefficient patterns, such as redundant transformation steps, unnecessary joins, or overly frequent data loads. These can all be redesigned to balance cost, speed, and reliability.
Operational Readiness and Disaster Recovery
Ensuring pipelines are resilient to service failures is another key area of focus. The DEA-C01 exam assesses how well you can implement disaster recovery plans for data systems. This includes setting up replication between regions, automating backups, and testing restore procedures regularly. Candidate should know how to prioritize data based on business criticality and apply different recovery time and recovery point objectives.
Operational readiness also includes setting up playbooks, conducting regular tests, and preparing for rolling deployments. Blue-green deployments or canary testing methods are essential in reducing the impact of faulty pipeline updates. Certification holders are expected to maintain system uptime while continuously improving and updating pipeline components.
Monitoring service quotas, managing resource limits, and ensuring availability zones are configured correctly is also part of being operationally ready. These aspects prevent downtime caused by scaling failures or configuration oversights and ensure long-term stability in high-throughput environments.
Performance Optimization and Query Tuning
One of the most critical aspects of data engineering is optimizing performance at various levels of the pipeline. A well-architected data pipeline is not only accurate but also efficient and cost-effective.
At the storage layer, partitioning is a powerful technique that reduces the amount of data scanned in queries. Tools like Amazon Athena, Redshift, and EMR benefit significantly when data is partitioned effectively. Instead of scanning an entire dataset, queries can scan only the relevant partitioned sections.
Columnar storage formats such as Parquet and ORC provide performance benefits through compression and column-level operations. They also reduce data retrieval times when used in conjunction with query engines that support predicate pushdown.
Materialized views and caching strategies can also accelerate analytics. In Redshift, for example, materialized views precompute complex joins and aggregations, reducing runtime costs.
Another powerful optimization strategy is denormalization. While normalization helps in transactional systems, analytical queries tend to perform better on denormalized tables, which reduce joins and improve I/O efficiency.
For streaming workloads, ensuring windowed aggregations and watermarking are implemented correctly can prevent performance degradation and event pile-ups. Misconfigured watermarking can lead to unbounded state and memory overflow, which slows down the system or causes failure.
Proper indexing, workload management queues, and distribution styles in Redshift also play a key role in performance tuning. For example, even distribution reduces data skew, and key-based distribution helps with join performance.
Mastering these techniques means developing an intuition for which optimizations to apply depending on the volume, velocity, and variety of data.
Monitoring and Troubleshooting Failures
Monitoring is a foundational skill for any data engineer. Without adequate visibility into systems and pipelines, troubleshooting becomes guesswork.
Tools like Amazon CloudWatch are essential for observing metrics and logs in real time. These include memory usage, CPU utilization, network traffic, and error rates. CloudWatch Alarms allow for real-time alerting, which can trigger automated recovery scripts or notifications.
Amazon OpenSearch and CloudTrail also contribute to observability. While OpenSearch is useful for log aggregation and querying logs across distributed environments, CloudTrail provides audit trails for API-level interactions with AWS services, which is vital for tracking root causes of failures.
When a pipeline fails, understanding whether it is a transient failure or systemic issue is the first diagnostic step. Transient issues such as network failures or API throttling can be handled with retries and exponential backoff strategies.
Systemic issues such as memory leaks, code bugs, or permission errors require deeper introspection. In these scenarios, one must inspect job logs, memory allocation, and service-specific error messages.
Handling retries safely is crucial. Idempotency becomes a fundamental concept when retrying failed operations. If the same operation is repeated, it should not lead to duplicate data or inconsistencies.
Additionally, setting up dead-letter queues in streaming or event-driven architectures can help isolate and analyze problematic events without halting the entire pipeline.
For batch systems, failure recovery strategies can include checkpointing, incremental processing, and restartable ETL jobs.
Security and Compliance in Data Engineering
Security is not just about preventing unauthorized access but also about ensuring data is stored, transmitted, and processed securely. The certification emphasizes applying the principle of least privilege to every component of the pipeline.
Fine-grained access control can be managed using AWS Identity and Access Management (IAM), resource-based policies, and Lake Formation permissions. This ensures that users and services only access data necessary for their roles.
Data encryption is mandatory for compliance with industry standards. AWS provides encryption both in transit and at rest using tools like KMS (Key Management Service). S3, RDS, Redshift, and even DynamoDB all support encryption options.
When working with personally identifiable information (PII), it’s important to enforce masking, tokenization, or pseudonymization of data. Techniques like column-level encryption or use of Data Loss Prevention (DLP) patterns can help prevent accidental exposure.
Compliance audits often require access logs and data usage reports. Setting up trails using AWS CloudTrail, VPC flow logs, and access logs helps demonstrate adherence to regulatory requirements.
Automated compliance frameworks can be set up using AWS Config rules. These help monitor compliance continuously by checking the configuration of AWS resources against best practices or organizational policies.
Another useful strategy is data classification, where tags or metadata are added to datasets to denote sensitivity levels. These tags can be used to automate controls such as encryption, access restriction, or retention policies.
The importance of secure credential management cannot be overstated. Use of Secrets Manager or Parameter Store ensures that credentials are not hardcoded or exposed in code repositories.
Cost Optimization and Resource Efficiency
Data engineering at scale can incur significant cloud costs if not optimized. Understanding how to balance performance with cost efficiency is essential.
Storing large volumes of data in high-cost storage classes without access patterns justifies switching to archival classes like S3 Glacier. Lifecycle policies can automatically transition objects based on age or last access time.
Compression reduces storage cost and accelerates queries. Formats like Parquet not only save space but also reduce scan costs in Athena and Redshift Spectrum.
In managed data services like Glue or EMR, selecting the correct worker type and job configuration impacts cost significantly. For example, Glue jobs can be optimized by tuning worker memory and parallelism, and using job bookmarks to avoid redundant processing.
Using spot instances for EMR clusters can reduce costs, especially for non-critical or retryable workloads. However, one must handle potential termination gracefully by persisting intermediate state and enabling retries.
For Redshift, setting concurrency scaling and auto suspend can help manage resources without overprovisioning. Reserved instances or usage-based pricing models must be evaluated based on predictable workloads.
Billing reports, cost explorer, and budgets with alerts help keep data teams aligned with financial goals.
A proactive approach to resource tagging helps categorize cost allocation by project, team, or client, and supports internal chargeback models.
Future Trends and Strategic Skill Development
The field of data engineering is rapidly evolving. As data volumes and complexity grow, so does the demand for new capabilities.
One growing area is the use of lake house architecture. It merges the benefits of data lakes and data warehouses, allowing both structured and unstructured data to be queried and governed in a unified manner.
Serverless data engineering is another trend, allowing teams to focus on transformation logic instead of infrastructure management. Services such as Glue, Athena, and Lambda support this model.
Data observability is gaining traction. This includes monitoring data quality, freshness, volume, and lineage in an automated manner. It helps ensure trustworthy data pipelines and timely delivery.
Another emerging domain is real-time analytics. Systems must support stream ingestion, processing, and dashboarding in near real-time. Technologies like Kinesis, Flink, and Managed Kafka are central to this evolution.
Skills like SQL optimization, Python scripting, and knowledge of distributed systems remain foundational. However, new skills around workflow orchestration (e.g., Airflow), data contracts, and domain-driven design are becoming increasingly valuable.
Platform engineering for data—where platform teams create reusable infrastructure patterns for analytics teams—is a rising organizational model. Understanding shared responsibility in such setups is key to building robust systems.
Being certification-ready is no longer about memorizing services, but about developing systems thinking, tradeoff analysis, and a feedback-driven development approach.
Long-Term Career Value of the Certification
This certification is more than a credential; it is a validation of hands-on experience in building production-grade data platforms. It aligns with the real-world expectations of hiring managers and technical leads.
The skills assessed reflect end-to-end ownership of data pipelines, not just theoretical knowledge. It prepares individuals to contribute to large-scale data transformation projects, analytics modernization, and cross-functional collaboration.
This certification opens pathways to roles beyond traditional data engineering, such as data architect, analytics lead, and cloud data strategist.
It also demonstrates a candidate’s ability to work with modern cloud-native services, understand tradeoffs between serverless and managed models, and implement best practices in performance, security, and compliance.
The long-term value lies in how the certification helps bridge the gap between raw data and actionable insights at scale. As data becomes central to every business, the certified professional’s role becomes indispensable.
Conclusion
Pursuing the AWS Certified Data Engineer – Associate certification opens up a path not only to validate technical competency but also to grow professionally in a fast-evolving field. It offers a well-rounded perspective on the AWS ecosystem and pushes candidates to go beyond theoretical knowledge by applying practical data engineering skills. From data ingestion and transformation to optimization and governance, the exam covers critical capabilities that reflect real-world job responsibilities.
This certification empowers data engineers to better understand how to design scalable pipelines, implement secure data workflows, and improve system performance within cloud environments. It sets a benchmark for excellence by encouraging hands-on expertise with core AWS services and architectural best practices. The journey may appear technical and complex, but with consistent preparation and practical experience, candidates can bridge their knowledge gaps and gain mastery over the required domains.
Ultimately, achieving the certification is not just about passing an exam. It’s about acquiring the confidence to solve meaningful data challenges, make informed decisions in cloud-based projects, and contribute to data-driven innovation across industries. Whether you're starting out or advancing in your data engineering career, this credential reinforces your value in any organization aiming to harness the full potential of cloud data systems.
Pass your Amazon AWS Certified Data Engineer - Associate DEA-C01 certification exam with the latest Amazon AWS Certified Data Engineer - Associate DEA-C01 practice test questions and answers. Total exam prep solutions provide shortcut for passing the exam by using AWS Certified Data Engineer - Associate DEA-C01 Amazon certification practice test questions and answers, exam dumps, video training course and study guide.
-
Amazon AWS Certified Data Engineer - Associate DEA-C01 practice test questions and Answers, Amazon AWS Certified Data Engineer - Associate DEA-C01 Exam Dumps
Got questions about Amazon AWS Certified Data Engineer - Associate DEA-C01 exam dumps, Amazon AWS Certified Data Engineer - Associate DEA-C01 practice test questions?
Click Here to Read FAQ -
-
Top Amazon Exams
- AWS Certified Generative AI Developer - Professional AIP-C01 - AWS Certified Generative AI Developer - Professional AIP-C01
- AWS Certified Solutions Architect - Associate SAA-C03 - AWS Certified Solutions Architect - Associate SAA-C03
- AWS Certified Solutions Architect - Professional SAP-C02 - AWS Certified Solutions Architect - Professional SAP-C02
- AWS Certified AI Practitioner AIF-C01 - AWS Certified AI Practitioner AIF-C01
- AWS Certified Cloud Practitioner CLF-C02 - AWS Certified Cloud Practitioner CLF-C02
- AWS Certified Security - Specialty SCS-C03 - AWS Certified Security - Specialty SCS-C03
- AWS Certified Machine Learning Engineer - Associate MLA-C01 - AWS Certified Machine Learning Engineer - Associate MLA-C01
- AWS Certified Advanced Networking - Specialty ANS-C01 - AWS Certified Advanced Networking - Specialty ANS-C01
- AWS Certified CloudOps Engineer - Associate SOA-C03 - AWS Certified CloudOps Engineer - Associate SOA-C03
- AWS Certified DevOps Engineer - Professional DOP-C02 - AWS Certified DevOps Engineer - Professional DOP-C02
- AWS Certified Data Engineer - Associate DEA-C01 - AWS Certified Data Engineer - Associate DEA-C01
- AWS Certified Developer - Associate DVA-C02 - AWS Certified Developer - Associate DVA-C02
- AWS Certified Security - Specialty SCS-C02 - AWS Certified Security - Specialty SCS-C02
- AWS Certified SysOps Administrator - Associate - AWS Certified SysOps Administrator - Associate (SOA-C02)
-
Purchase Amazon AWS Certified Data Engineer - Associate DEA-C01 Exam Training Products Individually
Last Week Results!
Get PDF Version of AWS Certified Data Engineer - Associate DEA-C01 Questions & Answers
With the PDF Version of the exam questions, you can study at any time and place, which are convenient to you. This means that you can work with the AWS Certified Data Engineer - Associate DEA-C01 Questions & Answers PDF Version on your PC or use it on your portable device while on the way to your work or home. The PDF exam file also offers you the possibility to print it and use this printed version if you prefer it over the digital one.
Since the file is in the .pdf format, you can open it with a wide range of programs and applications, including Google Docs, OpenOffice, and Adobe Acrobat Reader DC. It is a convenient and easy-to-use option that will help you master new knowledge and skills with relevant materials.
* PDF Version is an add-on to your purchase of AWS Certified Data Engineer - Associate DEA-C01 Questions & Answers and can't be purchased separately.
Only Registered Members can Download Exam Demo Questions & Answers
Please fill out your email address below in order to exam demo Questions & Answers.
Registration is Free and Easy, You Simply need to provide a valid email address.
- Trusted by hundreds of IT Certification Candidates Every Month
- 1200+ Exams Available
- Instant download After Registration