Google Professional Machine Learning Engineer
- Exam: Professional Machine Learning Engineer
- Certification: Professional Machine Learning Engineer
- Certification Provider: Google

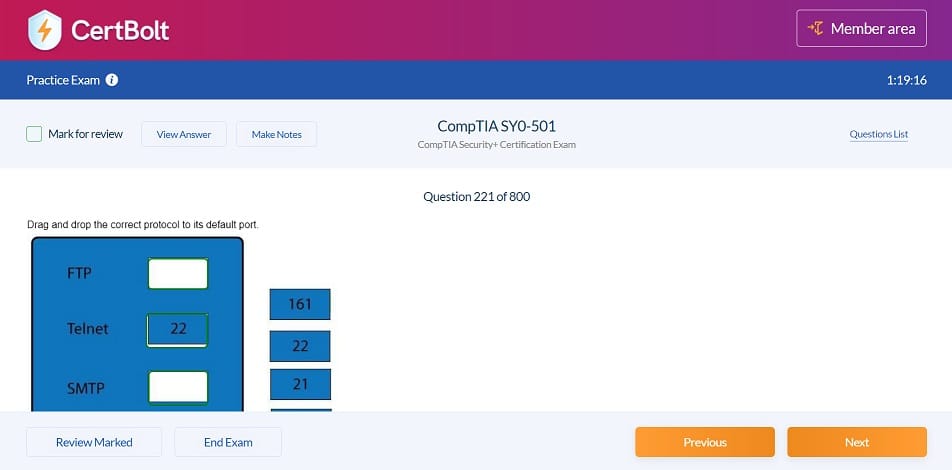
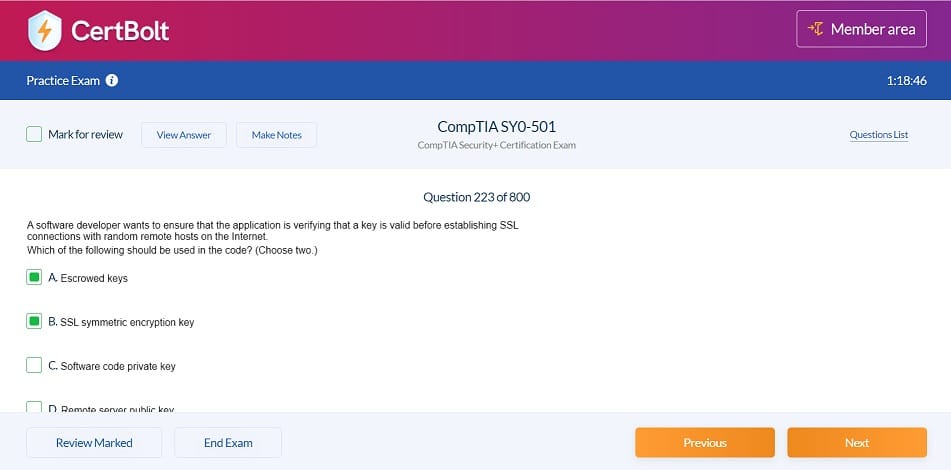
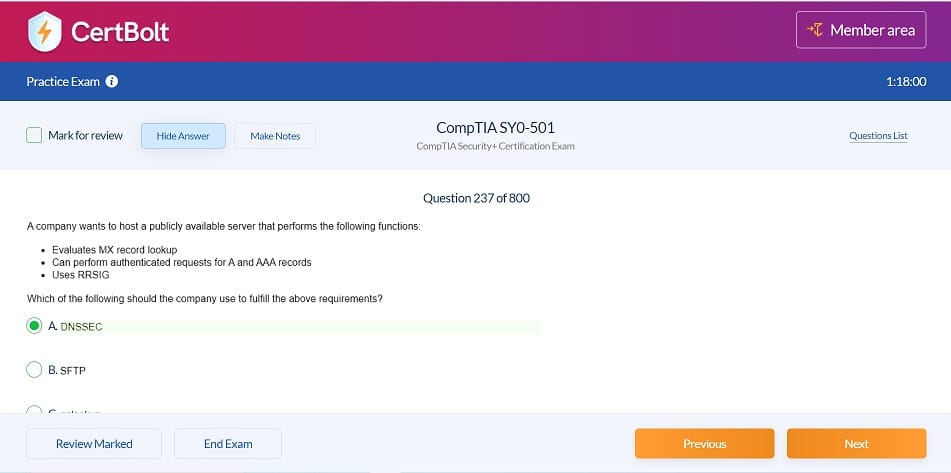
100% Updated Google Professional Machine Learning Engineer Certification Professional Machine Learning Engineer Exam Dumps
Google Professional Machine Learning Engineer Professional Machine Learning Engineer Practice Test Questions, Professional Machine Learning Engineer Exam Dumps, Verified Answers
-
-

Professional Machine Learning Engineer Questions & Answers
339 Questions & Answers
Includes 100% Updated Professional Machine Learning Engineer exam questions types found on exam such as drag and drop, simulation, type in, and fill in the blank. Fast updates, accurate answers for Google Professional Machine Learning Engineer Professional Machine Learning Engineer exam. Exam Simulator Included!
-

Professional Machine Learning Engineer Online Training Course
69 Video Lectures
Learn from Top Industry Professionals who provide detailed video lectures based on 100% Latest Scenarios which you will encounter in exam.
-

Professional Machine Learning Engineer Study Guide
376 PDF Pages
Study Guide developed by industry experts who have written exams in the past. Covers in-depth knowledge which includes Entire Exam Blueprint.
-
-
Google Professional Machine Learning Engineer Certification Practice Test Questions, Google Professional Machine Learning Engineer Certification Exam Dumps
Latest Google Professional Machine Learning Engineer Certification Practice Test Questions & Exam Dumps for Studying. Cram Your Way to Pass with 100% Accurate Google Professional Machine Learning Engineer Certification Exam Dumps Questions & Answers. Verified By IT Experts for Providing the 100% Accurate Google Professional Machine Learning Engineer Exam Dumps & Google Professional Machine Learning Engineer Certification Practice Test Questions.
Introduction to Google Professional Machine Learning Engineer Certification
The field of artificial intelligence and machine learning has grown exponentially over the past decade, becoming a cornerstone of technological innovation across industries. Organizations increasingly depend on data-driven solutions, making the demand for skilled professionals in machine learning higher than ever before. The Google Professional Machine Learning Engineer Certification is a prestigious credential that validates a professional’s ability to design, build, and deploy machine learning models in production environments. Unlike general data science or analytics certifications, this certification emphasizes practical application of machine learning techniques using Google Cloud Platform (GCP) tools. It not only demonstrates technical expertise but also showcases a professional’s ability to solve real-world business problems through machine learning.
This certification is designed for engineers, data scientists, and AI practitioners who are looking to formalize their knowledge and skills in machine learning. By earning this credential, professionals prove that they have mastered both the theoretical understanding and practical implementation of machine learning pipelines, data processing, model deployment, and ethical AI considerations. The certification also highlights an individual’s proficiency in using Google Cloud services such as Vertex AI, TensorFlow, BigQuery ML, and other GCP tools that are essential for scalable machine learning solutions.
The increasing adoption of AI in various sectors has created a competitive environment where certified machine learning engineers stand out significantly. Organizations now prefer professionals who can not only create models but also ensure that these models are optimized, ethical, and aligned with business objectives. As such, the Google Professional Machine Learning Engineer Certification serves as both a knowledge benchmark and a career accelerator for aspiring AI professionals.
Exam Overview and Structure
The Google Professional Machine Learning Engineer exam is designed to evaluate a candidate’s ability to apply machine learning concepts in practical scenarios. The exam includes multiple-choice and scenario-based questions that test both theoretical knowledge and hands-on skills. Candidates are expected to demonstrate proficiency in designing machine learning models, implementing data pipelines, evaluating model performance, and deploying solutions in production. The exam duration is typically two hours, allowing candidates sufficient time to analyze complex scenarios and provide accurate solutions.
The exam is structured around several key domains, each representing essential areas of competency in machine learning. These domains include designing and building ML models, preparing and processing data, developing and optimizing ML pipelines, deploying models to production, and ensuring ethical and responsible AI practices. Candidates are expected to have practical experience in each domain, as the exam emphasizes real-world application rather than purely academic knowledge.
Understanding the exam structure is crucial for effective preparation. The questions are designed to simulate real-world challenges, requiring candidates to make decisions based on incomplete data, business constraints, and technical limitations. This approach ensures that certified professionals are not only theoretically competent but also capable of making informed decisions under real-world conditions. Furthermore, the exam evaluates proficiency in using GCP tools, requiring candidates to demonstrate practical knowledge of services such as Vertex AI, TensorFlow, Cloud Storage, BigQuery, and AI Platform Pipelines.
Key Skills Assessed
The certification assesses a broad range of skills that are essential for any professional working in machine learning. One of the primary skills is data preparation and feature engineering. Candidates must demonstrate the ability to clean, preprocess, and transform raw data into formats suitable for machine learning models. This includes handling missing values, encoding categorical variables, normalizing numerical features, and performing feature selection to optimize model performance. Data quality is critical, as the accuracy of any model depends on the reliability and completeness of the input data.
Another core skill assessed is model development and training. Candidates must show proficiency in selecting appropriate algorithms for specific tasks, building models, and tuning hyperparameters to maximize performance. This involves understanding different types of models, such as regression, classification, clustering, and neural networks. Candidates are also expected to demonstrate knowledge of advanced machine learning techniques, including deep learning architectures, reinforcement learning, and ensemble methods. The ability to evaluate model performance using metrics such as accuracy, precision, recall, F1 score, and area under the curve (AUC) is also crucial.
Model deployment and operations are equally important. The exam evaluates a candidate’s ability to deploy models in production environments, monitor their performance, and manage their lifecycle. This includes setting up automated pipelines for continuous training, testing, and validation, as well as implementing strategies for model versioning and rollback. Candidates must also demonstrate knowledge of scalable deployment practices, ensuring that models can handle large volumes of data and maintain low latency during inference.
Ethical AI practices are increasingly becoming a critical component of machine learning certification. Candidates are expected to demonstrate awareness of bias, fairness, and responsible AI principles. This includes identifying potential biases in datasets, implementing techniques to mitigate bias, and ensuring that models do not produce discriminatory or harmful outcomes. Ethical considerations are not only important for compliance but also for maintaining the trust and credibility of AI solutions.
Google Cloud Platform Tools for ML Engineers
A key differentiator of the Google Professional Machine Learning Engineer Certification is its emphasis on Google Cloud Platform tools. Candidates are expected to have hands-on experience with GCP services, which provide end-to-end solutions for machine learning workflows. Vertex AI, for example, is a comprehensive platform for building, deploying, and scaling ML models. It allows engineers to manage datasets, train models using AutoML or custom pipelines, and deploy models to production with minimal infrastructure overhead.
TensorFlow, Google’s open-source machine learning framework, is another critical tool for candidates. Proficiency in TensorFlow enables engineers to design deep learning models, implement neural network architectures, and perform advanced optimization. TensorFlow’s integration with GCP services like Vertex AI allows seamless deployment and monitoring of models in production environments.
BigQuery ML is an innovative tool that enables engineers to create and execute machine learning models directly within Google’s BigQuery data warehouse. This allows for faster experimentation and model development using SQL queries without the need for extensive coding. Candidates are also expected to be familiar with AI Platform Pipelines, which facilitate automated ML workflows, ensuring that models are reproducible, scalable, and easy to maintain.
Preparing for the Exam
Effective preparation for the Google Professional Machine Learning Engineer Certification requires a structured approach. One of the first steps is understanding the exam guide provided by Google. This guide outlines the domains covered, the types of questions, and the skills expected. Candidates should review this guide thoroughly to identify areas of strength and weakness, creating a focused study plan based on their existing knowledge.
Hands-on practice is essential. Candidates should spend significant time working with GCP tools, building models, creating pipelines, and deploying solutions in controlled environments. Practical experience helps reinforce theoretical knowledge and ensures that candidates can handle real-world scenarios during the exam. Using datasets from public sources or internal projects allows for experimentation and skill development.
Online courses, labs, and training programs are valuable resources for exam preparation. Many platforms offer targeted learning paths that align with the exam domains, providing both theoretical instruction and practical exercises. Candidates should focus on exercises that simulate real-world machine learning challenges, such as handling unstructured data, building end-to-end pipelines, and optimizing model performance under constraints.
Mock exams are another critical tool for preparation. They allow candidates to experience the timing and pressure of the actual exam, helping to identify knowledge gaps and areas requiring additional focus. Reviewing incorrect answers and understanding the reasoning behind correct solutions strengthens both problem-solving skills and domain knowledge.
Data Preparation and Feature Engineering
Data preparation is often the most time-consuming and critical aspect of machine learning. Candidates must be adept at cleaning raw data, handling missing values, detecting outliers, and transforming data into formats suitable for model training. Feature engineering, the process of creating meaningful input features from raw data, is equally important. This includes normalizing numerical features, encoding categorical variables, and performing dimensionality reduction to improve model performance.
Understanding the nuances of data preparation is crucial for avoiding biased or inaccurate models. Engineers must be able to identify patterns, relationships, and anomalies within datasets, ensuring that the input data aligns with business objectives. Feature selection techniques, such as recursive feature elimination, correlation analysis, and principal component analysis, are essential skills that candidates must demonstrate. These techniques reduce model complexity, improve performance, and enhance interpretability.
Model Development and Training
The core of machine learning engineering lies in model development. Candidates must be capable of selecting the most appropriate algorithm based on the nature of the problem, the type of data, and the desired outcome. For regression tasks, algorithms like linear regression, decision trees, and gradient boosting may be appropriate. Classification tasks require models such as logistic regression, support vector machines, or deep learning architectures.
Deep learning, particularly neural networks, is a significant component of the certification. Candidates must understand the architecture of neural networks, including convolutional neural networks for image processing, recurrent neural networks for sequential data, and transformer-based models for natural language processing. Hyperparameter tuning, regularization, and optimization techniques like stochastic gradient descent are also essential skills.
Evaluating model performance is critical. Candidates must be proficient in using metrics such as accuracy, precision, recall, F1 score, mean squared error, and ROC-AUC. They must also understand cross-validation techniques, overfitting, underfitting, and strategies for model improvement. Proper evaluation ensures that models are reliable, generalizable, and suitable for deployment in production environments.
Model Deployment and Operations
Deploying machine learning models in production is a complex process that requires careful planning and monitoring. Candidates are expected to demonstrate the ability to deploy models on GCP services, manage model versions, and implement continuous integration and delivery pipelines. Scalability is a critical consideration, as production models must handle large volumes of data and maintain low latency.
Monitoring deployed models is essential for maintaining performance over time. Engineers must be able to detect model drift, performance degradation, and anomalies, implementing retraining or adjustment strategies as needed. Automated pipelines, logging, and alerting systems are integral to operational success, ensuring that models continue to provide accurate and reliable predictions.
Ethical AI and Responsible Practices
Ethics and responsible AI practices are increasingly important in modern machine learning. Candidates must demonstrate awareness of bias, fairness, privacy, and transparency in AI solutions. Identifying potential biases in datasets, implementing mitigation strategies, and ensuring that models operate fairly across diverse populations are key responsibilities of ML engineers.
Responsible AI also involves compliance with legal, regulatory, and organizational standards. Candidates must understand the implications of AI decisions, communicate results transparently, and prioritize user trust. These principles are not only ethical requirements but also critical for building sustainable and trustworthy AI solutions.
Understanding Machine Learning Problem Formulation
A critical skill for any machine learning engineer is the ability to accurately formulate problems. Problem formulation involves translating real-world business challenges into machine learning tasks that can be addressed with algorithms and models. This process requires a clear understanding of the objectives, constraints, available data, and desired outcomes. A poorly formulated problem can lead to models that are technically accurate but practically useless.
Machine learning problems can generally be categorized into regression, classification, clustering, or reinforcement learning tasks. Regression problems predict continuous values, such as sales forecasting or temperature prediction. Classification problems categorize inputs into predefined labels, such as spam detection or fraud identification. Clustering involves grouping similar data points without predefined labels, useful in customer segmentation or anomaly detection. Reinforcement learning, a more advanced domain, involves training agents to take sequential actions in environments to maximize cumulative rewards.
An engineer must also define success metrics early in the problem formulation stage. Selecting the right evaluation metric ensures that the model aligns with business goals. For example, accuracy may not be sufficient in imbalanced classification problems where metrics like precision, recall, or F1 score are more relevant. Understanding the impact of false positives and false negatives on the business is crucial to aligning machine learning objectives with organizational priorities.
Data Collection and Integration
Once the problem is formulated, data collection becomes the next critical step. High-quality data is the foundation of effective machine learning solutions. Engineers must identify relevant data sources, ensure data integrity, and integrate datasets from various channels. Data may come from internal databases, external APIs, IoT devices, or streaming platforms. Each source has unique characteristics that affect preprocessing, storage, and model performance.
Integration of diverse datasets requires careful attention to data consistency and compatibility. Engineers must resolve differences in schema, units, and formats, ensuring that the resulting dataset is cohesive and reliable. Data from multiple sources may have varying levels of granularity, timestamps, or missing values. Addressing these issues is essential to prevent biased models or inaccurate predictions.
Additionally, data collection must adhere to privacy regulations and ethical standards. This includes anonymizing personally identifiable information, obtaining proper consent for data usage, and following industry-specific compliance requirements. Ensuring ethical collection and integration of data safeguards the organization from legal risks and maintains trust with users and stakeholders.
Data Preprocessing Techniques
Raw data is rarely suitable for immediate use in machine learning models. Data preprocessing involves cleaning, transforming, and standardizing data to improve model accuracy and efficiency. Common preprocessing steps include handling missing values, removing duplicates, encoding categorical variables, scaling numerical features, and normalizing distributions. Each preprocessing decision affects model performance, interpretability, and computational efficiency.
Handling missing values can involve deletion, imputation, or predictive modeling. Deleting rows or columns may be appropriate when missing values are minimal, whereas imputation techniques like mean, median, or mode replacement are preferable for larger gaps. Advanced techniques, such as K-nearest neighbors or regression-based imputation, may be used for more complex datasets.
Encoding categorical variables is essential for models that require numerical input. Techniques include one-hot encoding, label encoding, or embedding representations. Choosing the right encoding method depends on the algorithm used, the number of categories, and potential ordinal relationships. Feature scaling, including min-max normalization and standardization, ensures that features contribute equally to the model’s learning process, preventing domination by features with larger numerical ranges.
Outlier detection and handling are also critical in preprocessing. Outliers can skew model performance, leading to inaccurate predictions. Engineers must identify outliers using statistical methods, visualization, or clustering techniques, then decide whether to remove, transform, or retain them based on business context.
Feature Engineering and Selection
Feature engineering transforms raw data into meaningful input features that enhance model performance. It involves creating new variables, combining existing ones, and extracting patterns that improve the predictive power of the model. Feature engineering requires both domain knowledge and statistical expertise. For instance, in a retail sales prediction problem, combining date features to create “day of the week” or “holiday indicator” features can provide additional predictive insights.
Feature selection is equally important, as redundant or irrelevant features can reduce model efficiency and increase overfitting risk. Techniques for feature selection include correlation analysis, recursive feature elimination, tree-based feature importance, and regularization methods like Lasso regression. Selecting the right subset of features improves model interpretability, reduces computational cost, and often enhances accuracy.
Automated feature engineering tools, such as feature transformers in Vertex AI, can accelerate the process, but human oversight is essential. Engineers must validate that engineered features align with domain knowledge and business context, ensuring that they contribute meaningful predictive information.
Model Selection and Algorithm Evaluation
Choosing the right algorithm is one of the most important decisions in machine learning. Model selection depends on the type of problem, data characteristics, computational resources, and desired interpretability. For regression tasks, linear regression, decision trees, or gradient boosting models may be appropriate. Classification problems often employ logistic regression, support vector machines, random forests, or neural networks. Clustering tasks can utilize k-means, hierarchical clustering, or DBSCAN algorithms.
Engineers must also consider model complexity, scalability, and training time. Simple models may perform adequately for smaller datasets and are easier to interpret, while complex models like deep neural networks may achieve higher accuracy on large datasets but require significant computational resources. Balancing accuracy, efficiency, and interpretability is key to model selection.
Evaluation metrics guide algorithm choice and optimization. For regression, metrics like mean squared error, mean absolute error, and R-squared are commonly used. Classification metrics include accuracy, precision, recall, F1 score, and area under the ROC curve. In imbalanced datasets, focusing on precision-recall metrics is often more effective than accuracy alone. Engineers must also consider cross-validation techniques to assess model generalization and prevent overfitting.
Model Training and Hyperparameter Tuning
Training a model involves adjusting its parameters to minimize errors on the training dataset. Engineers must select appropriate loss functions, optimization algorithms, and training techniques. For example, gradient descent and its variants are commonly used to update model weights iteratively. Batch size, learning rate, and number of epochs are critical hyperparameters that influence training efficiency and convergence.
Hyperparameter tuning further improves model performance by identifying optimal configurations. Techniques such as grid search, random search, and Bayesian optimization are commonly employed. Automated hyperparameter tuning tools in Vertex AI streamline this process, enabling engineers to explore multiple configurations efficiently. Proper tuning balances model accuracy, generalization, and computational cost, ensuring that the final model performs well on unseen data.
Overfitting and underfitting are common challenges during training. Overfitting occurs when a model performs well on training data but poorly on test data, often due to excessive complexity or noise. Underfitting happens when a model is too simplistic to capture underlying patterns. Engineers use regularization methods, dropout techniques, early stopping, and cross-validation to address these issues.
Model Evaluation and Validation
Once a model is trained, rigorous evaluation is necessary to assess its reliability and performance. Evaluation involves testing the model on unseen data and comparing predictions against actual outcomes. Splitting datasets into training, validation, and test sets is a standard practice to ensure unbiased performance assessment. Cross-validation techniques, such as k-fold validation, provide additional robustness by evaluating the model across multiple data splits.
Evaluation metrics depend on the problem type and business objectives. Regression models may be assessed using mean squared error or R-squared, while classification models rely on metrics such as accuracy, precision, recall, and F1 score. Confusion matrices, ROC curves, and lift charts provide visual insights into model performance and areas for improvement. Engineers must also analyze error patterns to identify potential biases or data issues that may affect predictions.
Model validation is a continuous process, particularly in dynamic environments where data distributions may change over time. Engineers must monitor for data drift, concept drift, and model degradation, updating models as necessary to maintain accuracy and reliability. Establishing automated monitoring pipelines ensures that models remain effective in production environments.
Deployment Strategies and Production Considerations
Deploying machine learning models into production requires careful planning to ensure scalability, reliability, and maintainability. Engineers must consider deployment architecture, resource allocation, model versioning, and integration with existing systems. Google Cloud Platform provides tools such as Vertex AI for seamless model deployment, enabling real-time predictions, batch processing, and scalable APIs.
Production models must be monitored continuously to detect performance degradation or operational issues. Metrics such as latency, throughput, error rates, and prediction quality provide insights into model health. Automated retraining pipelines, version control, and rollback strategies are critical for maintaining robust deployments. Engineers must also address security, compliance, and data privacy concerns during deployment, particularly when handling sensitive information.
A/B testing and shadow deployments are common strategies for validating production models before full rollout. These approaches allow engineers to compare new models against existing ones, measure performance in real-world conditions, and mitigate potential risks. Continuous monitoring and feedback loops ensure that deployed models remain aligned with business objectives and deliver consistent value.
Scalable Machine Learning Pipelines
Building scalable machine learning pipelines is essential for handling large datasets, complex workflows, and frequent model updates. Pipelines automate data preprocessing, feature engineering, model training, evaluation, and deployment, reducing manual effort and ensuring consistency. Vertex AI Pipelines, TensorFlow Extended (TFX), and Cloud Composer are tools that facilitate pipeline automation and orchestration.
Scalable pipelines must be modular, maintainable, and reproducible. Engineers design components that can be independently updated, tested, and replaced without disrupting the entire workflow. Containerization and orchestration technologies, such as Docker and Kubernetes, enhance scalability and portability. By implementing robust pipelines, engineers ensure that machine learning workflows can accommodate growth, evolving datasets, and changing business requirements.
Continuous Integration and Continuous Deployment (CI/CD) for ML
CI/CD practices are increasingly applied to machine learning to ensure reliable and repeatable model updates. Continuous integration involves automating code integration, testing, and validation, while continuous deployment automates model release into production environments. These practices improve collaboration, reduce errors, and accelerate time-to-market for ML solutions.
In ML projects, CI/CD pipelines include steps for data validation, model training, evaluation, testing, and deployment. Automated alerts, logging, and monitoring ensure that any issues are detected early, enabling engineers to take corrective action. Integrating CI/CD practices with GCP services streamlines operations, enhances reproducibility, and reduces operational risks associated with model updates.
Advanced Machine Learning Techniques
As machine learning applications grow in complexity, engineers must develop expertise in advanced techniques that go beyond basic algorithms. These techniques include ensemble methods, deep learning, natural language processing, reinforcement learning, and unsupervised learning methods. Mastery of these approaches allows engineers to tackle challenging problems and optimize model performance for a variety of applications.
Ensemble methods are particularly effective in improving predictive accuracy. Techniques such as bagging, boosting, and stacking combine multiple models to create a more robust and reliable solution. Bagging reduces variance by averaging predictions from multiple models trained on different subsets of data, while boosting sequentially trains models to correct errors from previous iterations. Stacking involves combining predictions from several models using a meta-learner. Each ensemble method addresses specific challenges in model performance and can be adapted depending on the data and problem type.
Deep learning has become a critical area in modern machine learning, particularly for tasks involving images, audio, or complex sequential data. Neural networks, including convolutional neural networks (CNNs) for image processing, recurrent neural networks (RNNs) for sequential data, and transformer-based architectures for natural language processing, enable engineers to capture intricate patterns that traditional models cannot. Understanding neural network architectures, activation functions, loss functions, and optimization methods is essential for developing effective deep learning solutions.
Natural Language Processing and Text-Based Models
Natural language processing (NLP) is an important domain within machine learning that focuses on the interaction between machines and human language. Engineers working with text data must be proficient in preprocessing techniques such as tokenization, stemming, lemmatization, and stop-word removal. Feature extraction methods, including term frequency-inverse document frequency (TF-IDF) and word embeddings like Word2Vec or GloVe, transform textual information into numerical formats suitable for modeling.
Modern NLP often leverages deep learning and transformer-based models. Transformers, including architectures such as BERT and GPT, enable context-aware representations of language, improving tasks such as sentiment analysis, machine translation, and text summarization. Engineers must also understand sequence modeling, attention mechanisms, and fine-tuning pretrained models to achieve optimal results. Text-based models require careful handling of vocabulary size, sequence length, and computational efficiency to ensure scalability.
Unsupervised Learning and Clustering
Unsupervised learning is a category of machine learning that identifies patterns and structures in data without labeled outcomes. Clustering is a primary unsupervised method used for grouping similar data points based on defined metrics. Common clustering algorithms include k-means, hierarchical clustering, and DBSCAN. Each algorithm has specific strengths and is suitable for different types of data distributions and applications.
Dimensionality reduction techniques, such as principal component analysis (PCA) and t-distributed stochastic neighbor embedding (t-SNE), are often employed alongside clustering to reduce computational complexity and highlight underlying data patterns. Engineers must evaluate cluster quality using metrics like silhouette score, Davies-Bouldin index, or inertia to ensure meaningful segmentation. Unsupervised learning is particularly valuable in exploratory data analysis, anomaly detection, and customer segmentation, providing insights that guide further modeling decisions.
Reinforcement Learning Fundamentals
Reinforcement learning (RL) is an advanced machine learning paradigm where an agent learns to make sequential decisions by interacting with an environment. The agent receives feedback in the form of rewards or penalties and adjusts its strategy to maximize cumulative rewards over time. RL has applications in robotics, game development, autonomous vehicles, and recommendation systems.
Key concepts in reinforcement learning include states, actions, rewards, policies, value functions, and the exploration-exploitation trade-off. Engineers must understand how to formulate RL problems, define appropriate reward structures, and implement algorithms such as Q-learning, deep Q-networks, and policy gradient methods. While RL is computationally intensive, mastering its principles allows engineers to solve complex problems where sequential decision-making is critical.
Model Interpretability and Explainability
As machine learning models become more complex, ensuring interpretability and explainability is crucial. Stakeholders, regulators, and end-users must understand how models make decisions, especially in high-stakes domains such as finance, healthcare, and law. Techniques such as feature importance analysis, partial dependence plots, SHAP values, and LIME provide insights into model behavior and decision rationale.
Engineers must balance model complexity with interpretability, particularly when deploying models in production. While deep learning models may achieve higher accuracy, they can be less transparent than simpler models. Explainable AI techniques allow engineers to bridge this gap, providing both predictive performance and actionable insights. Transparency also supports ethical AI practices, helping to identify bias, discrimination, or unintended consequences in model predictions.
Ethical Considerations in AI
Ethical considerations are central to responsible AI deployment. Engineers must proactively identify and mitigate biases in datasets and models, ensuring fairness across different demographic groups. Bias can arise from historical data, sampling methods, or feature selection, and failing to address it can lead to discriminatory outcomes. Techniques such as reweighting, resampling, adversarial debiasing, and fairness-aware algorithms help reduce bias and improve model equity.
Privacy is another key concern in AI. Compliance with regulations such as GDPR and HIPAA is essential when handling personal or sensitive data. Data anonymization, encryption, and secure storage practices protect user information while allowing for effective model training. Engineers must also consider the societal impact of AI solutions, ensuring that models do not cause harm or perpetuate inequities. Ethical AI is not merely a compliance requirement but a critical factor in maintaining trust, credibility, and long-term sustainability of AI systems.
Feature Store and Data Management
Managing features consistently across machine learning pipelines is essential for scalability and reproducibility. Feature stores provide centralized repositories for storing, versioning, and sharing features across projects. Google Cloud’s Vertex AI Feature Store enables engineers to manage feature consistency between training and serving environments, reducing feature drift and improving model reliability.
Feature engineering at scale requires careful version control, monitoring, and documentation. Engineers must track feature transformations, dependencies, and data lineage to ensure reproducibility. Centralized management also facilitates collaboration among teams, allowing multiple projects to leverage high-quality features without redundant engineering efforts. Effective feature management is a key component of robust, production-ready machine learning pipelines.
Model Optimization and Performance Tuning
Optimizing model performance involves both algorithmic and system-level improvements. Algorithmically, engineers may tune hyperparameters, experiment with regularization techniques, and explore advanced architectures to improve predictive accuracy. System-level optimizations include distributed training, GPU acceleration, and memory-efficient implementations, particularly for large datasets and deep learning models.
Performance tuning also involves addressing trade-offs between accuracy, latency, and computational cost. Engineers must evaluate model performance in the context of production requirements, ensuring that predictions are accurate, timely, and resource-efficient. Profiling tools, automated hyperparameter tuning, and monitoring frameworks support continuous optimization, enabling models to adapt to evolving data and business needs.
Continuous Monitoring and Model Maintenance
Deploying models into production is not a one-time task; continuous monitoring and maintenance are essential for long-term success. Engineers must track model performance, detect drift, and respond to changes in data distribution or business context. Monitoring involves collecting metrics such as accuracy, latency, throughput, error rates, and prediction consistency.
Automated retraining pipelines enable models to adapt to new data while maintaining performance. Version control, rollback strategies, and logging ensure that updates are traceable and reversible. Engineers must also implement alerting mechanisms to detect anomalies or failures in real time, minimizing disruptions to production systems. Proactive monitoring and maintenance safeguard model reliability, accuracy, and operational efficiency.
Scalable Infrastructure for Machine Learning
Building scalable infrastructure is critical for managing large-scale machine learning projects. Cloud platforms like Google Cloud provide resources for compute, storage, and orchestration, enabling engineers to handle growing datasets and complex workflows efficiently. Tools such as Kubernetes, Docker, and managed services like Vertex AI simplify deployment, scaling, and maintenance.
Engineers must design infrastructure that balances cost, performance, and reliability. Strategies include horizontal scaling, load balancing, distributed training, and automated resource allocation. Scalability ensures that machine learning solutions can handle increasing demand without compromising accuracy or latency. Proper infrastructure planning also supports collaboration, reproducibility, and operational continuity across teams.
Automation and MLOps Practices
Machine learning operations, or MLOps, integrates development, deployment, and monitoring to create reliable, automated workflows. MLOps practices include continuous integration, continuous delivery, pipeline automation, model versioning, and reproducibility. By implementing MLOps, engineers can streamline end-to-end workflows, reduce errors, and accelerate deployment cycles.
Automation is particularly important for repetitive tasks such as data preprocessing, feature engineering, model training, evaluation, and deployment. Tools like Vertex AI Pipelines and TensorFlow Extended (TFX) facilitate automated workflows, enabling engineers to focus on experimentation and optimization. MLOps practices ensure that machine learning projects are maintainable, scalable, and aligned with organizational goals.
Collaboration and Communication
Successful machine learning projects require collaboration between data engineers, data scientists, business analysts, and stakeholders. Engineers must communicate technical concepts, model insights, and limitations in a clear and actionable manner. Visualization tools, dashboards, and reports help bridge the gap between technical teams and decision-makers.
Collaboration also involves code reviews, documentation, and shared workflows. Engineers must ensure that models, datasets, and pipelines are well-documented, versioned, and reproducible. Effective communication and collaboration enhance project efficiency, knowledge sharing, and long-term maintainability of machine learning solutions.
Preparing for Real-World Challenges
Applying machine learning in real-world scenarios involves navigating challenges that extend beyond model development. Data quality issues, missing information, imbalanced datasets, and evolving business requirements are common obstacles. Engineers must adopt flexible approaches, continuously evaluate assumptions, and iterate on solutions to address these challenges effectively.
Scenario-based thinking is essential. Engineers must anticipate edge cases, unexpected inputs, and changing environments, designing robust models and pipelines that can handle variability. Real-world readiness also involves ethical considerations, regulatory compliance, scalability planning, and operational monitoring. Preparing for these challenges ensures that machine learning solutions deliver tangible business value over time.
Cloud-Native Machine Learning Solutions
Cloud-native machine learning is an approach that leverages cloud infrastructure to design, build, and deploy ML models efficiently. Cloud platforms such as Google Cloud Platform provide scalable compute resources, managed services, and automated tools that reduce operational complexity. Engineers can focus on model design, feature engineering, and optimization rather than infrastructure management.
Using cloud-native solutions allows teams to rapidly experiment, iterate, and deploy models while maintaining consistency across environments. Services like Vertex AI, BigQuery ML, and AI Platform Pipelines integrate seamlessly with storage, compute, and orchestration systems. Engineers can leverage managed GPUs and TPUs for deep learning, ensuring that models can process large datasets and train efficiently. Cloud-native design also enhances reliability, as managed services provide fault tolerance, automated updates, and monitoring capabilities.
Data Engineering for Machine Learning
Data engineering plays a crucial role in machine learning, providing clean, organized, and accessible data for model development. Engineers must build robust pipelines to ingest, process, and store data from multiple sources. Tools like Cloud Dataflow, BigQuery, and Cloud Storage enable scalable and efficient data handling.
Data engineers ensure that datasets are consistent, complete, and transformed into formats suitable for modeling. They handle challenges such as schema evolution, missing data, streaming data ingestion, and real-time processing. Collaboration between data engineers and ML engineers ensures that machine learning models are trained on reliable data, enhancing accuracy, reproducibility, and scalability. Feature stores further facilitate the reuse of high-quality features across multiple ML projects, improving efficiency and consistency.
AutoML and Model Automation
AutoML is a growing area of machine learning that enables automated model selection, hyperparameter tuning, and optimization. Google Cloud provides AutoML services that allow engineers to create high-performing models with minimal manual intervention. AutoML is particularly useful for engineers who want to focus on business problem-solving rather than the technical intricacies of model development.
While AutoML accelerates experimentation, engineers must still evaluate model quality, monitor performance, and ensure that solutions align with business objectives. Understanding how to interpret AutoML outputs, integrate automated pipelines, and maintain reproducibility is critical for scaling machine learning solutions in production. AutoML complements traditional model development by providing rapid baseline models, which can later be refined using custom approaches.
Handling Big Data for Machine Learning
The ability to process and analyze big data is essential for modern machine learning applications. Large datasets provide richer information for model training but require specialized techniques to manage computational complexity. Distributed computing frameworks, cloud storage, and batch processing pipelines enable engineers to work with massive datasets efficiently.
Techniques such as sampling, feature selection, and dimensionality reduction help reduce computational load while preserving information content. Streaming data requires real-time processing pipelines, where models can make predictions as new data arrives. Engineers must balance accuracy, latency, and resource utilization when handling big data, ensuring that ML models remain practical and responsive in production environments.
Time Series and Forecasting Models
Time series analysis is an important machine learning domain used for predicting trends over time. Applications include sales forecasting, stock price prediction, energy consumption, and demand planning. Engineers must understand temporal patterns, seasonality, trends, and cyclical behavior to build accurate forecasting models.
Common techniques include autoregressive integrated moving average (ARIMA), exponential smoothing, and recurrent neural networks such as LSTMs. Feature engineering for time series involves creating lag variables, rolling averages, and trend indicators. Evaluating forecast models requires metrics such as mean absolute error, root mean squared error, and mean absolute percentage error. Engineers must also account for changing patterns, missing data, and anomalies when developing time series solutions.
Computer Vision and Image Analysis
Computer vision is a specialized area of machine learning that focuses on extracting information from images and videos. Engineers working in this domain must understand image preprocessing techniques, including resizing, normalization, augmentation, and color channel manipulation. Convolutional neural networks are commonly used for image classification, object detection, and segmentation tasks.
Advanced architectures like ResNet, Inception, and EfficientNet provide state-of-the-art performance for image analysis tasks. Engineers must optimize models for speed and accuracy, particularly when deploying in real-time systems. Transfer learning, where pretrained models are fine-tuned for specific tasks, is an effective strategy for accelerating model development and reducing computational requirements.
Reinforcement Learning in Production
Applying reinforcement learning in production environments introduces unique challenges, including delayed feedback, reward design, and environment simulation. Engineers must design reward structures that align with business objectives, ensuring that agents learn desirable behaviors without unintended consequences.
Production RL solutions require robust monitoring and evaluation, as agents may encounter states or actions not observed during training. Techniques such as online learning, policy adaptation, and safe exploration help mitigate risks. Engineers must also address computational demands, as RL often involves extensive simulation or iterative learning. Deploying RL models successfully requires careful planning, continuous monitoring, and integration with broader system architectures.
Model Interpretability in Complex Systems
As ML models grow in complexity, interpretability becomes increasingly important. Deep learning models, ensemble methods, and multi-stage pipelines can achieve high accuracy but are often opaque. Engineers must use interpretability tools and techniques to provide insights into how models make decisions.
Partial dependence plots, SHAP values, LIME, and counterfactual explanations enable engineers to communicate model behavior to stakeholders, validate fairness, and detect potential biases. Interpretability supports ethical AI practices and helps organizations maintain compliance with regulatory standards. Engineers must strike a balance between model complexity, performance, and transparency, ensuring that ML solutions are both accurate and understandable.
Bias Detection and Fairness
Detecting and mitigating bias is a core responsibility of machine learning engineers. Bias can originate from historical data, sampling methods, feature selection, or model design. Unchecked bias can lead to unfair predictions, reputational damage, and legal consequences.
Techniques for addressing bias include data reweighting, resampling, adversarial debiasing, fairness constraints, and algorithmic adjustments. Engineers must evaluate models across demographic groups, identify disparities, and implement mitigation strategies. Ensuring fairness is an ongoing process, requiring monitoring, retraining, and validation to maintain equitable outcomes over time.
Model Security and Privacy
Securing machine learning models and data is essential to protect sensitive information and maintain trust. Engineers must address vulnerabilities such as data poisoning, model inversion, and adversarial attacks. Implementing encryption, access controls, secure storage, and differential privacy techniques helps protect data during training and deployment.
Privacy regulations, including GDPR and HIPAA, mandate strict controls on personal and sensitive data. Engineers must design workflows that comply with these regulations while maintaining model performance. Secure and privacy-conscious practices are integral to responsible AI, ensuring that ML solutions do not compromise user confidentiality or organizational integrity.
Monitoring and Alerting for Deployed Models
Continuous monitoring is necessary to ensure that deployed models remain accurate and reliable over time. Engineers track performance metrics such as accuracy, latency, error rates, and data distribution changes. Automated alerting systems notify engineers of anomalies or performance degradation, enabling prompt intervention.
Monitoring also includes detecting concept drift, where the statistical properties of input data change over time, potentially reducing model performance. Retraining strategies, pipeline adjustments, and real-time evaluation help maintain model efficacy. Proactive monitoring safeguards production systems, ensuring that ML solutions continue to deliver business value consistently.
Scaling Machine Learning Workflows
Scaling ML workflows involves designing systems that can handle increasing data volumes, complexity, and frequency of updates. Distributed training, horizontal scaling, containerization, and orchestration technologies support scalable deployments. Vertex AI, Kubernetes, and Cloud Composer are examples of tools that facilitate scaling ML workflows efficiently.
Engineers must plan for resource allocation, load balancing, and failover strategies to ensure robustness. Scalable workflows also enable reproducibility, version control, and collaboration across teams. Efficient scaling allows organizations to deploy ML solutions broadly while maintaining performance, reliability, and maintainability.
Collaboration and Team Management
Machine learning projects often require collaboration between data scientists, ML engineers, data engineers, and business stakeholders. Clear communication, shared workflows, and proper documentation are critical for successful collaboration. Engineers must ensure that datasets, features, models, and pipelines are accessible, versioned, and reproducible.
Collaboration also involves code reviews, standardized practices, and effective project management. By fostering a collaborative environment, teams can reduce duplication, accelerate experimentation, and improve overall solution quality. Knowledge sharing ensures that expertise is distributed across the team, enhancing the resilience and scalability of ML initiatives.
Continuous Learning and Skill Development
Machine learning is a rapidly evolving field, requiring engineers to continuously update their knowledge and skills. Emerging algorithms, frameworks, cloud services, and best practices constantly shape the landscape. Engineers must dedicate time to learning new tools, techniques, and approaches to remain competitive and effective.
Professional certifications, workshops, online courses, and hands-on projects support ongoing skill development. Engineers should also engage with the broader AI community to exchange insights, learn from real-world applications, and stay informed about ethical, regulatory, and technological developments. Continuous learning ensures that ML engineers can deliver innovative, reliable, and responsible solutions over time.
Career Opportunities for Certified ML Engineers
The Google Professional Machine Learning Engineer Certification opens a wide range of career opportunities for professionals in the AI and data science domains. Organizations across industries are seeking engineers who can design, implement, and optimize machine learning solutions. Certified ML engineers can pursue roles such as machine learning engineer, AI specialist, data scientist, deep learning engineer, AI consultant, and research scientist.
Companies value certified engineers for their verified expertise in end-to-end machine learning workflows, including data preparation, feature engineering, model development, deployment, and ethical AI practices. Certification signals to employers that the professional possesses practical skills and can handle real-world ML challenges. This recognition enhances career prospects, increases salary potential, and enables engineers to take on leadership roles in AI projects.
Industry Applications of Machine Learning
Machine learning is applied across a broad spectrum of industries, making certified engineers highly versatile. In finance, ML models power fraud detection, credit scoring, algorithmic trading, and risk management. Healthcare relies on predictive analytics, diagnostic models, patient monitoring, and personalized treatment recommendations. Retail and e-commerce use ML for recommendation systems, demand forecasting, and inventory optimization.
Other industries, including manufacturing, logistics, telecommunications, and energy, utilize machine learning to optimize operations, detect anomalies, and enhance predictive maintenance. Engineers must understand industry-specific challenges, data sources, and business goals to design effective ML solutions. The certification equips professionals with the skills to navigate these diverse applications confidently.
Salary and Career Growth
Certified machine learning engineers typically command higher salaries than non-certified peers due to their verified expertise and practical skills. Compensation varies by region, experience level, and industry, but professionals with Google certification are often among the top earners in AI-related roles. Beyond financial rewards, certification enhances career growth by opening doors to senior positions, leadership roles, and strategic responsibilities in AI initiatives.
Long-term career growth involves continuous learning, staying current with emerging technologies, and expanding expertise in specialized areas such as deep learning, reinforcement learning, NLP, and computer vision. Certified engineers who maintain proficiency in advanced techniques and cloud-native solutions are well-positioned to lead complex projects and contribute to organizational innovation.
Preparing for the Certification Exam
Effective preparation for the Google Professional Machine Learning Engineer exam requires a combination of theoretical understanding, hands-on practice, and strategic planning. Candidates should begin by reviewing the official exam guide to understand the key domains, question formats, and skill requirements. Mapping personal strengths and weaknesses against the exam objectives helps create a focused study plan.
Hands-on practice with Google Cloud services is essential. Engineers should gain experience with Vertex AI, TensorFlow, BigQuery ML, AI Platform Pipelines, and other tools that support end-to-end ML workflows. Practical experience ensures familiarity with the platform, model deployment processes, and pipeline automation. Experimenting with real datasets and building end-to-end projects enhances readiness for scenario-based exam questions.
Structured Learning Resources
Structured learning resources are critical for systematic preparation. Online courses, workshops, and official Google Cloud training programs provide a structured approach to mastering key concepts. Learning resources often include guided labs, coding exercises, and assessments that simulate real-world scenarios.
Engaging with learning platforms that provide project-based exercises allows candidates to apply theoretical knowledge in practical settings. This hands-on approach strengthens problem-solving skills and reinforces understanding of complex topics such as feature engineering, hyperparameter tuning, model evaluation, and ethical AI considerations.
Practice Exams and Simulations
Practice exams and simulations are invaluable tools for exam readiness. They help candidates familiarize themselves with question formats, time constraints, and difficulty levels. Simulating exam conditions improves time management, decision-making, and confidence. Reviewing incorrect answers and understanding the reasoning behind correct solutions reinforces learning and highlights areas requiring further study.
Candidates should aim to take multiple practice exams to identify patterns in question types, assess knowledge gaps, and refine problem-solving strategies. Practice exams also provide exposure to scenario-based questions, which are a significant component of the certification exam.
Time Management and Study Strategies
Effective time management is essential during preparation. Candidates should allocate dedicated study periods, balancing theoretical review, hands-on practice, and practice exams. Breaking down complex topics into manageable segments ensures steady progress and reduces overwhelm.
Active learning strategies, such as note-taking, summarizing concepts, and teaching others, enhance retention and understanding. Collaborative study groups or discussion forums provide opportunities for knowledge sharing, peer support, and exposure to diverse problem-solving approaches. Combining these strategies optimizes preparation efficiency and ensures comprehensive coverage of exam objectives.
End-to-End Machine Learning Projects
Completing end-to-end machine learning projects is one of the most effective ways to prepare for certification. Projects allow candidates to practice problem formulation, data collection, preprocessing, feature engineering, model selection, training, evaluation, and deployment. Realistic projects simulate industry scenarios and provide insights into practical challenges that may arise during model development.
Working on diverse projects strengthens the ability to handle varied data types, business requirements, and deployment constraints. Engineers gain experience with iterative development, hyperparameter tuning, pipeline automation, and performance monitoring. End-to-end projects provide a tangible portfolio that demonstrates expertise to employers and reinforces exam readiness.
Collaboration and Communication Skills
Machine learning engineers must excel in collaboration and communication. Projects often involve cross-functional teams, requiring clear articulation of technical concepts, model decisions, limitations, and business implications. Engineers must present findings to non-technical stakeholders, ensuring that models are understood, trusted, and actionable.
Documentation is a critical aspect of communication. Well-documented code, feature transformations, model architectures, and evaluation procedures facilitate reproducibility, knowledge transfer, and long-term maintainability. Collaborative practices, including code reviews and shared workflows, improve project quality, efficiency, and team synergy.
Real-World Case Studies
Studying real-world case studies enhances understanding of practical challenges and solutions in machine learning. Case studies provide insights into data quality issues, model selection dilemmas, deployment considerations, and ethical implications. Engineers learn to navigate trade-offs between accuracy, interpretability, latency, and resource constraints.
Analyzing successful and unsuccessful ML implementations helps engineers anticipate common pitfalls, identify best practices, and develop problem-solving strategies. Case studies also highlight the importance of cross-functional collaboration, monitoring, and continuous improvement in production environments.
Ethical AI in Practice
Applying ethical AI principles is a critical responsibility for certified ML engineers. Engineers must evaluate models for fairness, bias, transparency, and privacy. Ethical AI practices involve selecting unbiased datasets, monitoring model predictions, and implementing mitigation strategies to prevent discrimination.
Privacy considerations, including anonymization, secure storage, and compliance with regulations such as GDPR and HIPAA, are essential for responsible AI. Engineers must also assess the societal impact of models, ensuring that solutions do not cause harm or reinforce inequities. Ethical AI practices foster trust, credibility, and long-term sustainability of machine learning solutions.
Model Monitoring and Maintenance
Continuous monitoring and maintenance are essential for sustaining model performance in production. Engineers track metrics such as accuracy, latency, error rates, and data distribution changes. Concept drift, data drift, and evolving business requirements necessitate periodic model retraining and updates.
Automated monitoring pipelines, alerting systems, and version control facilitate proactive maintenance. Engineers must respond to anomalies, performance degradation, and emerging requirements to ensure that deployed models continue to deliver value. Effective monitoring and maintenance practices support reliability, scalability, and operational efficiency.
Scaling and Optimization
Scaling machine learning solutions involves designing workflows that can handle increasing data volumes, computational demands, and model complexity. Distributed training, containerization, and cloud orchestration technologies support scalable deployments. Engineers must optimize pipelines for resource utilization, latency, and throughput while maintaining model accuracy.
Performance tuning and optimization include hyperparameter adjustment, feature selection, dimensionality reduction, and algorithmic enhancements. Scaling strategies ensure that ML solutions remain responsive, efficient, and cost-effective, enabling organizations to deploy AI at enterprise levels.
Leadership and Strategic Impact
Certified machine learning engineers can contribute strategically to organizations by leading AI initiatives, mentoring teams, and guiding project direction. Leadership roles involve defining AI strategy, evaluating emerging technologies, and aligning ML solutions with business objectives. Engineers in leadership positions influence decision-making, drive innovation, and promote best practices in model development, deployment, and ethical AI.
Strategic impact extends to resource planning, collaboration across departments, and long-term solution sustainability. Engineers leverage certification knowledge to implement scalable, reproducible, and responsible ML solutions that deliver measurable value to the organization.
Preparing for Future AI Trends
The field of machine learning is rapidly evolving, with new algorithms, frameworks, and tools emerging continuously. Certified engineers must stay informed about AI trends such as foundation models, multimodal learning, reinforcement learning advancements, edge AI, and quantum machine learning.
Adapting to new technologies involves continuous learning, experimentation, and professional development. Engineers who proactively explore emerging trends, evaluate applicability, and integrate innovative techniques are well-positioned to lead future AI projects. Staying current ensures that ML solutions remain competitive, efficient, and aligned with evolving industry standards.
Professional Networking and Community Engagement
Engaging with the professional AI community enhances career growth, knowledge sharing, and collaboration opportunities. Conferences, workshops, online forums, and open-source contributions provide platforms for learning, networking, and sharing insights. Certified engineers benefit from exposure to diverse perspectives, real-world challenges, and emerging best practices.
Networking also creates opportunities for mentorship, collaboration on complex projects, and access to job opportunities. Active participation in the AI community strengthens professional reputation, supports continuous learning, and fosters relationships that facilitate career advancement.
Continuous Improvement and Learning Culture
Machine learning engineers thrive in environments that encourage continuous improvement and learning. Establishing a growth mindset involves regularly reviewing project outcomes, identifying areas for enhancement, and iterating on workflows. Engineers should document lessons learned, refine models, and explore new techniques to drive better results.
A culture of continuous learning ensures that engineers remain adaptable, innovative, and resilient in a rapidly changing technological landscape. It reinforces professional expertise, enhances solution quality, and contributes to organizational success.
Conclusion
The Google Professional Machine Learning Engineer Certification represents a comprehensive validation of technical expertise, practical skills, and professional readiness in machine learning. Certified engineers are equipped to handle end-to-end ML workflows, deploy models at scale, ensure ethical practices, and drive strategic impact.
This certification opens doors to diverse career opportunities, enhances salary potential, and positions professionals as leaders in AI-driven organizations. By mastering advanced techniques, leveraging cloud-native tools, and embracing continuous learning, certified ML engineers are well-prepared to tackle real-world challenges and contribute meaningfully to the evolving landscape of artificial intelligence.
Pass your next exam with Google Professional Machine Learning Engineer certification exam dumps, practice test questions and answers, study guide, video training course. Pass hassle free and prepare with Certbolt which provide the students with shortcut to pass by using Google Professional Machine Learning Engineer certification exam dumps, practice test questions and answers, video training course & study guide.
-
Google Professional Machine Learning Engineer Certification Exam Dumps, Google Professional Machine Learning Engineer Practice Test Questions And Answers
Got questions about Google Professional Machine Learning Engineer exam dumps, Google Professional Machine Learning Engineer practice test questions?
Click Here to Read FAQ -
-
Top Google Exams
- Professional Cloud Architect - Google Cloud Certified - Professional Cloud Architect
- Generative AI Leader - Generative AI Leader
- Professional Machine Learning Engineer - Professional Machine Learning Engineer
- Associate Cloud Engineer - Associate Cloud Engineer
- Professional Data Engineer - Professional Data Engineer on Google Cloud Platform
- Cloud Digital Leader - Cloud Digital Leader
- Professional Security Operations Engineer - Professional Security Operations Engineer
- Professional Cloud DevOps Engineer - Professional Cloud DevOps Engineer
- Professional Cloud Network Engineer - Professional Cloud Network Engineer
- Professional Cloud Security Engineer - Professional Cloud Security Engineer
- Associate Google Workspace Administrator - Associate Google Workspace Administrator
- Professional Cloud Developer - Professional Cloud Developer
- Professional Cloud Database Engineer - Professional Cloud Database Engineer
- Associate Data Practitioner - Google Cloud Certified - Associate Data Practitioner
- Professional ChromeOS Administrator - Professional ChromeOS Administrator
- Professional Google Workspace Administrator - Professional Google Workspace Administrator
-
Purchase Google Professional Machine Learning Engineer Exam Training Products Individually
Last Week Results!
Get Questions & Answers PDF Version
With the PDF Version of the exam questions, you can study at any time and place, which are convenient to you. This means that you can work with the Professional Machine Learning Engineer Questions & Answers PDF Version on your PC or use it on your portable device while on the way to your work or home. The PDF exam file also offers you the possibility to print it and use this printed version if you prefer it over the digital one.
Since the file is in the .pdf format, you can open it with a wide range of programs and applications, including Google Docs, OpenOffice, and Adobe Acrobat Reader DC. It is a convenient and easy-to-use option that will help you master new knowledge and skills with relevant materials.
* PDF Version is an add-on to your purchase of Professional Machine Learning Engineer Questions & Answers and can't be purchased separately.
Only Registered Members can Download Exam Demo Questions & Answers
Please fill out your email address below in order to download exam demo Questions & Answers.
Registration is Free and Easy, You Simply need to provide a valid email address.
- Trusted by hundreds of IT Certification Candidates Every Month
- 1200+ Exams Available
- Instant download After Registration