Databricks Certified Data Engineer Professional Bundle
- Exam: Certified Data Engineer Professional
- Exam Provider: Databricks

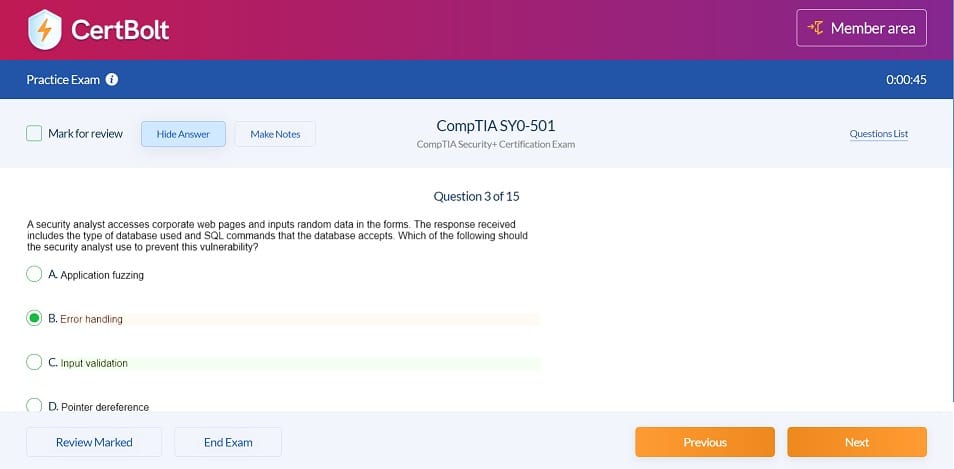
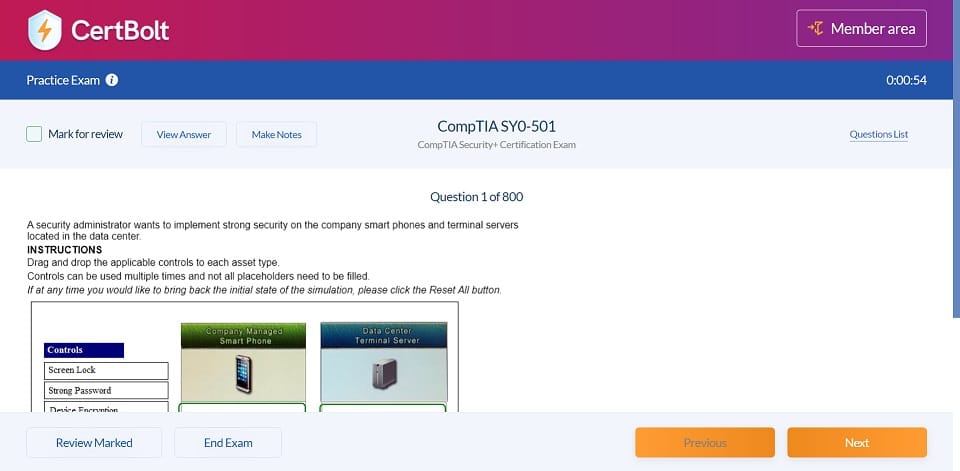
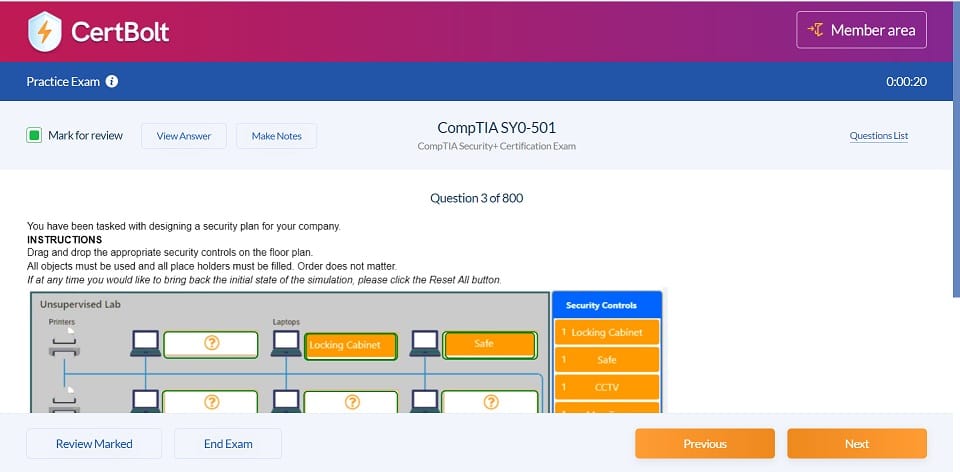
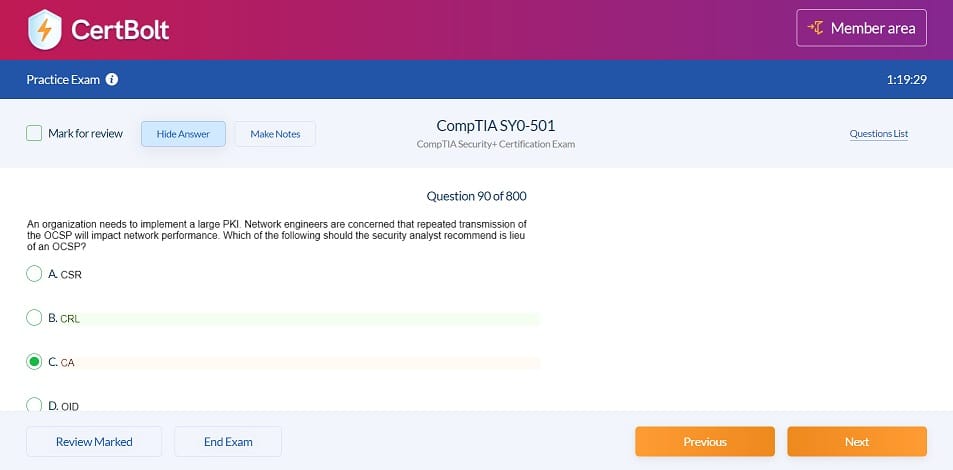
Latest Databricks Certified Data Engineer Professional Exam Dumps Questions
Databricks Certified Data Engineer Professional Exam Dumps, practice test questions, Verified Answers, Fast Updates!
-
-

Certified Data Engineer Professional Questions & Answers
339 Questions & Answers
Includes 100% Updated Certified Data Engineer Professional exam questions types found on exam such as drag and drop, simulation, type in, and fill in the blank. Fast updates, accurate answers for Databricks Certified Data Engineer Professional exam. Exam Simulator Included!
-

Certified Data Engineer Professional Online Training Course
33 Video Lectures
Learn from Top Industry Professionals who provide detailed video lectures based on 100% Latest Scenarios which you will encounter in exam.
-
-
Databricks Certified Data Engineer Professional Exam Dumps, Databricks Certified Data Engineer Professional practice test questions
100% accurate & updated Databricks certification Certified Data Engineer Professional practice test questions & exam dumps for preparing. Study your way to pass with accurate Databricks Certified Data Engineer Professional Exam Dumps questions & answers. Verified by Databricks experts with 20+ years of experience to create these accurate Databricks Certified Data Engineer Professional dumps & practice test exam questions. All the resources available for Certbolt Certified Data Engineer Professional Databricks certification practice test questions and answers, exam dumps, study guide, video training course provides a complete package for your exam prep needs.
Insider Tips for Excelling in the Databricks Certified Data Engineer Professional Exam
Passing the Databricks Certified Data Engineer Professional exam is a significant achievement for anyone working in data engineering. This certification validates the ability to design, build, and maintain scalable and reliable data solutions using Databricks. For data engineers, architects, or developers, the exam demonstrates expertise in handling complex data pipelines, performing large-scale data processing, and implementing advanced analytics. Unlike other certifications, this exam emphasizes not only theoretical knowledge but practical application, particularly in real-world scenarios where efficient data management is critical.
The exam covers multiple areas including data processing, Databricks tooling, data modeling, security and governance, monitoring and logging, and testing and deployment. Each area tests practical skills, meaning candidates must be able to perform tasks such as building structured streaming pipelines, optimizing queries, implementing security policies, and troubleshooting performance issues. Understanding the scope of the exam is crucial, as it allows candidates to focus on areas that have the most impact on day-to-day data engineering tasks.
Importance of Delta Lake and Structured Streaming
One of the most essential aspects of the exam is a deep understanding of Delta Lake. Delta Lake enables reliable, high-performance data storage and processing through ACID transactions and scalable metadata handling. Candidates must understand how transaction logs work and how they ensure data consistency in concurrent environments. Concepts like Change Data Capture and Delta Change Data Feed are integral to building pipelines that can handle incremental data efficiently.
Structured Streaming is another cornerstone of the exam. Candidates should be comfortable implementing streaming workflows, managing windows, handling late data, and applying watermarks to avoid inconsistencies. Real-world scenarios often require integrating streaming pipelines with batch processing, meaning that understanding the interplay between streaming and batch operations is vital. Candidates who master these topics can design systems that are not only functional but resilient under heavy workloads.
Databricks Tooling for Efficient Data Engineering
Databricks provides a wide array of tools for building and managing data workflows. Understanding clusters, jobs, libraries, and the CLI is critical to ensure smooth pipeline execution. Candidates are expected to know how to configure jobs for optimal performance, manage dependencies effectively, and automate workflows for recurring tasks. Additionally, knowledge of dbutils and other utilities can simplify tasks such as managing files, data movement, and resource monitoring.
Tooling knowledge is not just about performing tasks; it’s about optimizing for scale. For example, candidates should understand when to use interactive versus job clusters, how autoscaling impacts costs and performance, and how cluster libraries affect dependencies in multi-stage workflows. This practical understanding is what differentiates candidates who can handle real-world data challenges from those who simply memorize commands.
Advanced Data Modeling Techniques
Data modeling in the Databricks environment requires a solid grasp of the Medallion Architecture, which organizes data into bronze, silver, and gold layers. Understanding the rationale behind this structure is essential for designing pipelines that support both batch and streaming data efficiently. Candidates must also grasp Slowly Changing Dimensions and how they impact historical data storage and query performance.
Optimizing queries through techniques such as Z-ordering, partitioning, and caching is another critical skill. Candidates should know how to balance data storage optimization with query performance, ensuring that pipelines can handle large volumes of data without bottlenecks. Rare insights often come from understanding the trade-offs between different approaches, such as when partitioning may increase write time but improve read efficiency, or when Z-ordering reduces I/O for selective queries.
Security, Governance, and Compliance
Security and governance are not just exam topics; they are core aspects of real-world data engineering. Candidates should understand access control mechanisms, audit logging, and data governance policies. Managing sensitive data and complying with regulatory requirements requires more than basic ACL knowledge; it involves designing pipelines that can enforce data policies automatically and ensure that compliance is maintained even as data scales.
Governance extends to workflow management and monitoring. Implementing automated alerts, logging data access patterns, and auditing data transformations ensures that pipelines remain transparent and accountable. Exam candidates who focus on these areas not only prepare for the test but also acquire skills directly applicable in professional environments where data breaches and mismanagement can have significant consequences.
Preparing for the Exam
A structured study plan is key to success. Candidates should allocate time to both theoretical learning and hands-on practice. Realistic simulations of exam scenarios, including writing Spark and SQL queries, designing end-to-end pipelines, and troubleshooting performance issues, reinforce learning. Additionally, revisiting complex topics like streaming windows, transaction logs, and query optimization ensures readiness for any scenario the exam may present.
Advanced Testing and Deployment Strategies
Effective testing is a cornerstone of robust data engineering. Understanding how to implement unit tests, integration tests, and end-to-end workflow validation ensures that pipelines function correctly before reaching production. Unit testing focuses on individual transformations or logic steps, ensuring that each component behaves as expected. Integration testing verifies that multiple pipeline components work together correctly, especially when handling complex ETL workflows. End-to-end testing validates the entire data pipeline, confirming that data moves seamlessly from raw ingestion to the final curated output. Real-world testing requires simulating scenarios like late-arriving data, schema changes, or partial failures, which helps prepare for unexpected issues in production.
Deploying pipelines effectively requires a structured approach. Data engineers should understand how to manage version control, track code changes, and deploy updates without disrupting existing workflows. Automation tools and scripts can help orchestrate deployment processes, enabling rapid updates while minimizing risk. Additionally, implementing rollback mechanisms ensures that failures during deployment do not lead to data loss or inconsistencies. By simulating deployment processes during practice, candidates gain confidence in handling real-world scenarios where time-sensitive and accurate data delivery is crucial.
Monitoring and Performance Optimization
Monitoring data pipelines is essential to maintain reliability and performance. Understanding how to analyze execution logs, track job completion times, and identify bottlenecks allows engineers to optimize workflows. Performance tuning often involves identifying slow transformations, inefficient joins, or improper caching strategies. Profiling tools can highlight resource-heavy operations and suggest adjustments to improve efficiency. In real-world projects, minor inefficiencies can compound into significant delays, so optimizing each stage of the pipeline is crucial for scalable operations.
Data engineers also need to monitor resource usage and cost implications. Analyzing cluster utilization, memory consumption, and I/O patterns helps in designing pipelines that balance speed and cost-effectiveness. Dynamic scaling, partitioning strategies, and caching are critical tools for achieving this balance. Engineers who understand the interplay between data architecture and infrastructure can build systems that are both performant and economical.
Security and Data Governance
In modern data engineering, security and governance are inseparable from pipeline design. Implementing role-based access, encrypting sensitive data, and ensuring compliance with data retention policies protect both the organization and its customers. Engineers must anticipate scenarios where unauthorized access, accidental deletion, or misuse of data could occur. Building preventive measures, such as access audits, automated validation checks, and monitoring alerts, strengthens the overall security posture of data workflows.
Governance also involves maintaining transparency in data lineage and transformations. Understanding how each dataset is generated, modified, and consumed helps maintain trust in the system. Documenting pipeline processes and establishing clear ownership ensures accountability and facilitates troubleshooting when issues arise. Engineers who prioritize governance can provide auditable and compliant pipelines, which is essential for enterprise-scale operations.
Real-World Scenario Handling
Handling edge cases and unexpected data scenarios distinguishes expert data engineers. For instance, dealing with late-arriving data requires understanding windowing strategies and managing out-of-order records. Handling schema evolution involves anticipating changes in incoming datasets and ensuring downstream processes remain compatible. Engineers must also design fault-tolerant workflows that can recover from partial failures, data corruption, or network interruptions without manual intervention. Practicing these scenarios during preparation ensures readiness for complex production environments.
Additionally, performance tuning under varying data loads is a critical skill. Engineers should be able to anticipate the impact of increased data volumes, changing query patterns, and resource contention. Optimizing storage formats, partitioning schemes, and data compression techniques directly affects processing efficiency and cost. Engineers who master these skills can design systems that remain reliable and performant under high-demand conditions.
Strategic Approach to Learning
A strategic approach to mastering advanced data engineering concepts involves balancing theory with hands-on practice. Candidates should focus on understanding core principles, such as transaction handling, streaming processing, and query optimization, while simultaneously building and testing real pipelines. Simulated exercises, failure recovery scenarios, and performance tuning drills provide practical experience that theoretical study alone cannot achieve.
Structured study routines can also improve retention and application. Breaking down complex topics into digestible segments, followed by hands-on exercises, ensures deeper understanding. Regularly revisiting challenging areas, documenting findings, and experimenting with different approaches encourages creative problem-solving. Real-world data engineering often involves unforeseen challenges, so developing adaptability through practice is as valuable as mastering specific commands or tools.
Insights from Professional Practice
Experienced engineers often share that understanding the “why” behind each design decision is more important than memorizing commands. For example, knowing why partitioning improves query performance in certain situations but may hinder write operations allows for informed trade-offs. Similarly, grasping the principles behind streaming checkpointing, event-time processing, and failure recovery enables engineers to implement pipelines that are resilient and maintainable.
Collaboration skills are also vital. Real-world projects often involve multiple teams managing different components of a data ecosystem. Clear communication, shared documentation, and consistent conventions ensure pipelines operate smoothly and minimize errors. Understanding these professional practices alongside technical concepts provides a holistic preparation approach that goes beyond exam-focused learning.
Preparing for Unexpected Exam Scenarios
In examinations that test practical skills, unexpected scenarios or uncommon questions can appear. Preparing for these involves developing problem-solving strategies, such as breaking down complex questions, isolating subproblems, and applying fundamental principles rather than relying on memorized solutions. Practicing with diverse datasets, simulating failures, and experimenting with alternative approaches builds flexibility in handling novel challenges.
Time management during preparation and the exam itself is equally important. Practicing under timed conditions, prioritizing high-impact tasks, and reviewing answers systematically reduce the likelihood of errors. Candidates who train for both technical proficiency and strategic exam execution perform more confidently and consistently.
Building Long-Term Expertise
Ultimately, certification preparation should be seen as a pathway to long-term skill development rather than a short-term goal. Understanding advanced concepts, building practical experience, and adopting professional best practices ensures that the knowledge gained is applicable well beyond the exam. Engineers who embrace continuous learning, adapt to new tools and methods, and reflect on real-world challenges remain competitive and effective in their roles.
Mastering data engineering at a professional level involves more than passing an exam—it involves cultivating the ability to design scalable, secure, and resilient systems that can evolve with changing data landscapes. This combination of technical mastery, strategic thinking, and practical application defines successful data engineering practice.
Optimizing Data Pipelines for Scalability
Designing scalable data pipelines requires a deep understanding of how data grows and evolves over time. Efficient partitioning strategies are crucial to ensure that large datasets do not slow down processing. Engineers must balance the number of partitions to avoid excessive overhead while ensuring parallelism. Understanding how to leverage caching for frequently accessed data or intermediate results can dramatically improve performance. Additionally, choosing the right storage formats, such as columnar formats optimized for analytics, reduces I/O and speeds up queries. Scalability is not just about handling more data; it is also about maintaining performance as the system grows, which requires continuous monitoring and iterative optimization.
Delta Lake’s advanced features play a key role in scaling pipelines. Transaction logs allow for safe concurrent writes, while merge operations simplify data consolidation. Handling late-arriving data through structured streaming and watermarking ensures data accuracy without sacrificing throughput. Optimizing compaction strategies, Z-ordering, and vacuum operations ensures that storage remains efficient and queries execute faster even as datasets expand. Engineers who master these techniques can build pipelines that remain robust under variable data volumes and evolving business requirements.
Advanced Troubleshooting Techniques
Real-world data pipelines rarely run perfectly without issues. Understanding how to identify and troubleshoot bottlenecks is essential. Analyzing execution plans and job stages helps detect slow operations, skewed partitions, or inefficient joins. Engineers must be familiar with logging structures, cluster resource usage, and error propagation to pinpoint the root cause of failures quickly. Developing a systematic approach to troubleshooting ensures that problems are resolved efficiently, reducing downtime and data inconsistencies.
In addition to reactive troubleshooting, proactive monitoring can prevent many common issues. Setting up alerts for high latency, job failures, or unexpected data volume spikes allows engineers to address potential problems before they escalate. Simulating failure scenarios during pipeline development trains engineers to respond to unexpected conditions and enhances overall system reliability. Building resilience into pipelines through retries, checkpointing, and idempotent transformations ensures that recovery from failure is smooth and predictable.
Data Quality and Validation
Maintaining high data quality is critical for any production pipeline. Engineers must implement rigorous validation checks at each stage of processing. This includes schema validation, null or duplicate detection, and consistency checks across datasets. Automating these validations ensures that anomalies are detected early and do not propagate downstream, which can cause flawed analytics or business decisions.
Understanding how to design data quality frameworks is equally important. Techniques such as sampling, statistical profiling, and anomaly detection help identify irregularities in large-scale data. Monitoring trends over time allows engineers to detect gradual degradation in data quality, which is often harder to spot than sudden failures. Ensuring that validation processes scale alongside the dataset is a key aspect of sustainable pipeline design.
Streaming Data Challenges
Streaming data introduces unique challenges that require careful handling. Late-arriving events, out-of-order records, and high-throughput bursts can disrupt pipeline consistency. Windowing strategies, watermarking, and state management are critical tools for addressing these issues. Engineers must understand how to balance latency and completeness to ensure timely and accurate results.
Structured streaming with checkpointing ensures that pipelines can recover from failures without data loss. Efficient state management minimizes memory usage while maintaining the correctness of aggregations and joins. Monitoring streaming pipelines in real-time allows engineers to detect backlogs or skewed partitions and adjust resources or configurations accordingly. Mastering these techniques ensures that streaming systems remain resilient, accurate, and performant.
Advanced Query Optimization
Optimizing queries is a central aspect of building efficient data systems. Engineers must understand how to analyze query plans and identify resource-intensive operations. Techniques such as predicate pushdown, partition pruning, and selective caching reduce unnecessary computation. Understanding how join strategies impact performance, particularly in large datasets, allows engineers to make informed decisions about pipeline design.
Delta Lake and columnar storage formats provide opportunities for additional optimization. Data skipping, compaction, and Z-ordering reduce the amount of data scanned during queries. Combining these techniques with careful partitioning ensures that pipelines remain efficient even as data grows. Engineers who can anticipate performance bottlenecks and optimize proactively can maintain predictable execution times and resource utilization.
Security and Compliance in Data Pipelines
Securing pipelines is not limited to controlling access; it also involves maintaining integrity and traceability. Implementing role-based access ensures that only authorized users can view or modify sensitive data. Auditing data transformations and access patterns provides accountability and helps meet regulatory requirements. Encryption at rest and in transit protects data from unauthorized access, while automated checks detect tampering or inconsistencies.
Governance extends beyond security to maintaining clear data lineage. Tracking how data moves through various transformations ensures transparency and facilitates troubleshooting. Engineers should document key processes, transformations, and ownership to provide clarity across teams. Maintaining this discipline ensures that pipelines are not only secure but also auditable and reliable for long-term operations.
Handling Complex Data Models
Complex data models, including slowly changing dimensions and hierarchical datasets, require careful management. Engineers must ensure that updates do not overwrite critical historical data while maintaining query efficiency. Using advanced merge and update strategies helps maintain consistency across multiple layers of data. Modeling decisions should always consider both current requirements and potential future expansions.
Data engineers also need to account for multi-source integrations. Combining structured, semi-structured, and unstructured data requires normalization, validation, and enrichment techniques. Ensuring that these integrations do not introduce inconsistencies or degrade performance is key to building reliable pipelines. Well-designed models enable efficient analytics and reporting while supporting evolving business needs.
Practical Insights from Pipeline Design
Experienced engineers emphasize that design decisions should prioritize maintainability and flexibility. Modular pipeline architecture allows for easy updates and scaling without significant rewrites. Incorporating automated testing, logging, and monitoring into the design phase ensures long-term reliability. Additionally, adopting a mindset of continuous improvement helps identify opportunities to optimize performance, reduce costs, and enhance resilience.
Collaboration and communication are critical in complex data environments. Clear documentation, shared conventions, and coordinated deployment strategies prevent errors and facilitate knowledge transfer. Engineers who combine technical mastery with strategic planning are better equipped to handle real-world pipeline challenges.
Preparing for High-Stakes Scenarios
Practicing under simulated high-stakes conditions is an effective way to prepare for real-world challenges. Engineers should expose pipelines to extreme data volumes, schema changes, and failure conditions to test robustness. Time-sensitive processing and concurrent workload handling also benefit from realistic simulations. This approach ensures that systems remain reliable under stress and that engineers develop confidence in their ability to respond to unexpected issues.
Time management and prioritization are essential skills. Focusing on high-impact areas, breaking down complex problems, and maintaining composure under pressure improve overall efficiency. Engineers who develop these habits can navigate complex pipelines and operational challenges successfully.
Long-Term Skill Development
Mastery of advanced data engineering is a continuous journey. Beyond technical skills, engineers must cultivate analytical thinking, problem-solving abilities, and a strategic perspective. Understanding both system-level interactions and business requirements ensures that pipelines deliver value efficiently. Continuous learning, experimentation, and adaptation are essential for maintaining relevance in a rapidly evolving data landscape.
Developing expertise involves a balance between deep technical knowledge and professional judgment. Engineers who integrate optimization, monitoring, security, and governance into their workflows create pipelines that are not only effective but also sustainable. The ability to anticipate issues, adapt to change, and implement resilient solutions distinguishes top-performing data engineers.
Designing Future-Proof Data Architectures
Building a data architecture that can adapt to evolving business needs requires foresight and careful planning. Engineers must anticipate changes in data volume, complexity, and user requirements to avoid costly redesigns. Layered architecture, including raw, curated, and presentation layers, provides flexibility for analytics and reporting while ensuring data integrity. Choosing scalable storage solutions and compute resources allows the system to grow without major performance degradation. It is essential to design modular pipelines that can be modified or extended with minimal disruption.
Data lakes and lakehouse principles enable a unified approach to storage and analytics. Consolidating structured, semi-structured, and unstructured data in a single environment reduces duplication and simplifies management. Optimized file formats, such as columnar storage with built-in compression, enhance query performance while minimizing storage costs. Partitioning, clustering, and indexing strategies further ensure that data retrieval remains efficient even as datasets scale. Engineers who master these principles can create robust architectures capable of supporting complex workflows for years to come.
Leveraging Advanced Analytics and Machine Learning
Integrating advanced analytics and machine learning into pipelines requires careful coordination between data engineering and data science workflows. Data must be transformed, cleaned, and enriched before being used for modeling to ensure accuracy. Feature engineering and storage strategies must accommodate iterative experimentation and retraining without compromising existing pipelines. Efficient storage of large feature sets, along with reproducible transformation steps, ensures that models are both reliable and interpretable.
Real-time analytics introduces additional challenges. Streaming pipelines must handle high-throughput events while maintaining data consistency for immediate insights. State management, incremental aggregations, and windowed computations are critical for producing timely results. Engineers must collaborate closely with analytics teams to ensure that pipelines deliver data in formats suitable for both batch and real-time analysis, enabling faster decision-making across the organization.
Ensuring Data Reliability and Resilience
Reliability and resilience are fundamental to long-term pipeline success. Engineers must implement automated error detection, retry mechanisms, and failover strategies to handle transient issues without impacting downstream processes. Checkpointing, idempotent transformations, and versioned datasets ensure that pipelines can recover gracefully from unexpected failures.
Building resilience also involves monitoring dependencies and external data sources. Any upstream change, such as schema modification or data quality degradation, can propagate issues throughout the system. Automated alerts, anomaly detection, and proactive remediation processes help maintain data reliability. Engineers who prioritize resilience minimize downtime, reduce manual intervention, and build trust in the system among end-users.
Optimizing Performance in Complex Workflows
Performance optimization requires understanding both computational and storage characteristics of data systems. Efficient joins, selective column reads, and optimized shuffle operations reduce unnecessary computation. Partition pruning, caching, and proper use of materialized views enhance query speed while minimizing resource usage. Engineers must continuously monitor pipeline performance, analyzing execution metrics to identify bottlenecks and opportunities for improvement.
Load balancing across clusters and dynamic resource allocation help manage variable workloads without over-provisioning resources. Understanding how different operations affect memory, CPU, and I/O ensures that pipelines remain cost-effective while meeting performance targets. Engineers who combine proactive monitoring with iterative optimization can maintain predictable and reliable processing even under complex, multi-stage workflows.
Managing Security and Data Governance
Security and governance extend beyond access control to include comprehensive data stewardship. Data lineage, audit logging, and metadata management provide visibility into how data flows and transforms within pipelines. Engineers must enforce role-based access, implement encryption, and ensure compliance with regulatory frameworks while enabling legitimate analytics and operations.
Governance also involves establishing standardized practices for schema evolution, naming conventions, and documentation. Clear definitions of ownership, responsibilities, and transformation logic prevent confusion and reduce errors. By integrating governance into daily pipeline operations, engineers maintain data integrity and foster confidence in the reliability and security of their systems.
Handling Multi-Source and Heterogeneous Data
Modern pipelines often ingest data from diverse sources, including structured databases, APIs, streaming platforms, and semi-structured formats like JSON or XML. Managing these heterogeneous inputs requires robust transformation and validation processes. Engineers must normalize formats, enforce schema consistency, and handle missing or inconsistent values to ensure accurate downstream analytics.
Efficient ingestion strategies, such as batch processing for large volumes and streaming for real-time events, enable flexible pipeline designs. Engineers must balance latency, throughput, and processing complexity when designing multi-source workflows. Combining these practices with monitoring and alerting ensures that any source-related anomalies are quickly detected and resolved.
Automation, Orchestration, and Workflow Management
Automating pipeline workflows reduces human error and ensures repeatable, predictable processes. Orchestration frameworks allow complex dependencies to be managed efficiently, handling scheduling, retries, and conditional execution. Engineers should adopt modular designs, where independent tasks can be updated or replaced without impacting the overall workflow.
In addition to automation, testing and validation are essential. Unit testing, integration testing, and end-to-end validation ensure that pipelines operate as expected under various conditions. By combining automation with rigorous testing, engineers can deploy and maintain pipelines with confidence, reducing operational overhead and improving reliability.
Advanced Monitoring and Observability
Observability goes beyond basic logging and metrics, providing insights into pipeline health, performance, and data quality. Engineers should implement end-to-end monitoring, tracking execution times, resource usage, and anomaly patterns. Visualization tools, dashboards, and alerting systems allow teams to quickly identify and respond to potential issues.
Proactive observability also includes tracking trends over time. By analyzing historical performance and error patterns, engineers can anticipate potential failures, optimize resource allocation, and plan capacity expansions. This level of insight transforms pipeline management from reactive troubleshooting to strategic planning and continuous improvement.
Future Trends and Emerging Techniques
Data engineering is continuously evolving, with new technologies and techniques emerging regularly. Concepts such as serverless compute, hybrid transactional/analytical processing, and advanced data mesh architectures are shaping the future of data pipelines. Engineers must remain adaptable, learning to integrate new tools and approaches while maintaining stability and performance.
Continuous experimentation with optimization techniques, streaming strategies, and governance frameworks allows pipelines to stay current and efficient. Forward-looking engineers anticipate trends in data growth, analytics requirements, and cloud infrastructure, ensuring that their architectures remain relevant and capable of supporting future innovations.
Strategic Approaches to Pipeline Management
Successful pipeline management combines technical expertise with strategic thinking. Engineers must prioritize high-impact areas, balance short-term fixes with long-term improvements, and maintain a holistic view of data systems. Communication and collaboration across teams are critical to align engineering efforts with business goals.
Strategic pipeline management also includes lifecycle planning, from ingestion and transformation to storage, analysis, and archival. Engineers who integrate performance optimization, resilience, governance, and scalability into their workflows build pipelines that are both robust and adaptable. By combining technical mastery with strategic foresight, teams can deliver sustainable data solutions that support evolving organizational needs.
Continuous Learning and Improvement
Mastering complex data engineering pipelines is an ongoing process. Engineers must embrace continuous learning, experimenting with new techniques, reviewing performance metrics, and adopting best practices. Regular reflection on past successes and failures informs better design decisions and operational strategies.
Professional growth in this field requires curiosity, analytical thinking, and a willingness to adapt. Engineers who cultivate these qualities can navigate the challenges of modern data environments, implement innovative solutions, and maintain high-quality, reliable pipelines that deliver long-term value to organizations.
Final Words
Preparing for the Databricks Certified Data Engineer Professional exam is more than just memorizing concepts; it is about developing a deep understanding of modern data engineering practices and applying them in real-world scenarios. Success comes from balancing theoretical knowledge with hands-on experience, ensuring that you can design, optimize, and maintain data pipelines that are both efficient and reliable. Every step, from mastering data processing frameworks to implementing robust governance, contributes to building a strong foundation for handling large-scale, complex data systems.
The journey also requires strategic thinking. Understanding how data flows, where bottlenecks may occur, and how to optimize storage and compute resources allows engineers to create solutions that are scalable and resilient. Attention to security, observability, and workflow orchestration ensures that pipelines remain reliable under varying loads and evolving business requirements.
Ultimately, becoming proficient in data engineering is a continuous process. Emerging technologies, evolving best practices, and growing organizational data needs mean that learning never truly stops. By cultivating curiosity, adopting efficient workflows, and prioritizing hands-on experimentation, engineers can maintain an edge in the rapidly evolving landscape of big data. Achieving certification validates this expertise, but the true value lies in the practical skills and confidence gained along the way. Success in this field is about mastering not only tools and technologies but also the mindset to design systems that endure, scale, and drive meaningful insights for organizations.
Pass your Databricks Certified Data Engineer Professional certification exam with the latest Databricks Certified Data Engineer Professional practice test questions and answers. Total exam prep solutions provide shortcut for passing the exam by using Certified Data Engineer Professional Databricks certification practice test questions and answers, exam dumps, video training course and study guide.
-
Databricks Certified Data Engineer Professional practice test questions and Answers, Databricks Certified Data Engineer Professional Exam Dumps
Got questions about Databricks Certified Data Engineer Professional exam dumps, Databricks Certified Data Engineer Professional practice test questions?
Click Here to Read FAQ -
-
Top Databricks Exams
- Certified Data Engineer Associate - Certified Data Engineer Associate
- Certified Data Engineer Professional - Certified Data Engineer Professional
- Certified Generative AI Engineer Associate - Certified Generative AI Engineer Associate
- Certified Data Analyst Associate - Certified Data Analyst Associate
- Certified Machine Learning Associate - Certified Machine Learning Associate
- Certified Associate Developer for Apache Spark - Certified Associate Developer for Apache Spark
- Certified Machine Learning Professional - Certified Machine Learning Professional
-
Purchase Databricks Certified Data Engineer Professional Exam Training Products Individually
Last Week Results!
Get PDF Version of Certified Data Engineer Professional Questions & Answers
With the PDF Version of the exam questions, you can study at any time and place, which are convenient to you. This means that you can work with the Certified Data Engineer Professional Questions & Answers PDF Version on your PC or use it on your portable device while on the way to your work or home. The PDF exam file also offers you the possibility to print it and use this printed version if you prefer it over the digital one.
Since the file is in the .pdf format, you can open it with a wide range of programs and applications, including Google Docs, OpenOffice, and Adobe Acrobat Reader DC. It is a convenient and easy-to-use option that will help you master new knowledge and skills with relevant materials.
* PDF Version is an add-on to your purchase of Certified Data Engineer Professional Questions & Answers and can't be purchased separately.
Only Registered Members can Download Exam Demo Questions & Answers
Please fill out your email address below in order to exam demo Questions & Answers.
Registration is Free and Easy, You Simply need to provide a valid email address.
- Trusted by hundreds of IT Certification Candidates Every Month
- 1200+ Exams Available
- Instant download After Registration